ExeBench: An ML-Scale Dataset of Executable C Functions
前言:最近总是和数据集打交道,都自己想发一个数据集的论文了。Exebench 从名字上看就是一个充满可执行文件的数据集,为什么其地位重要?就是因为编译领域必须保证一切是可执行(可复现)的。所以这个数据集得以诞生。而且自己看过作者后才发现,作者之一居然是Michael O’Boyle,也是久闻大名了。但是可惜这一行居然还是被爱丁堡大学常年垄断…
该论文发表在 MAPS,是一个比较新的会议。参考评级可能在 CCF-C中文摘要
机器学习有望彻底改变编译和软件工程,但其发展往往受到可用数据集范围的限制。尤其是在从神经程序合成到机器学习指导的程序优化等一系列任务中,缺乏可运行的真实世界数据集。为了解决这一问题,我们引入了一个新的数据集——ExeBench。
ExeBench 旨在解决真实代码中的两个关键问题:
- 对外部类型和函数的引用
- 可扩展的输入/输出(IO)示例生成
ExeBench 是==首个公开可用的数据集==,它将来自 GitHub 的真实 C 代码与 IO 示例配对,使这些程序能够运行。我们开发了一套工具链,可以从 GitHub 抓取代码,分析代码,并生成可运行的代码片段。随后,我们使用多个指标分析了该基准测试套件,并证明它能代表真实世界的代码特征。
ExeBench 包含 450 万个可编译的 C 函数,其中 70 万个函数可执行。如此规模的可执行真实函数将为下一代基于机器学习的编程任务提供强大的支持。
既然是首个就有缺陷,当今缺乏的是一套数据集标准,来囊括更庞大的编译体系
引言
- 有很多数据集可以支持克隆检测、代码翻译、代码补全
- 但均不支持编译、反编译、程序合成
- AnghaBench 的缺陷在于依赖外部符号导致其不可执行
- Exebench 解决了这个问题,并提供了大量可执行文件(for 机器学习)
- 作者爬取了 Github,并使用了测试生成工具来自动生成 IO 对
总的贡献在于:
- 可执行 C 语言数据集
- 说明数据集的覆盖和代表性 (对于 Github)
- 一个制作数据集的方法
相关工作
- CodeNet
- ProgRes
- 可执行数据集有:
- CSNIPPEX
- 最相近数据集:Anghabench
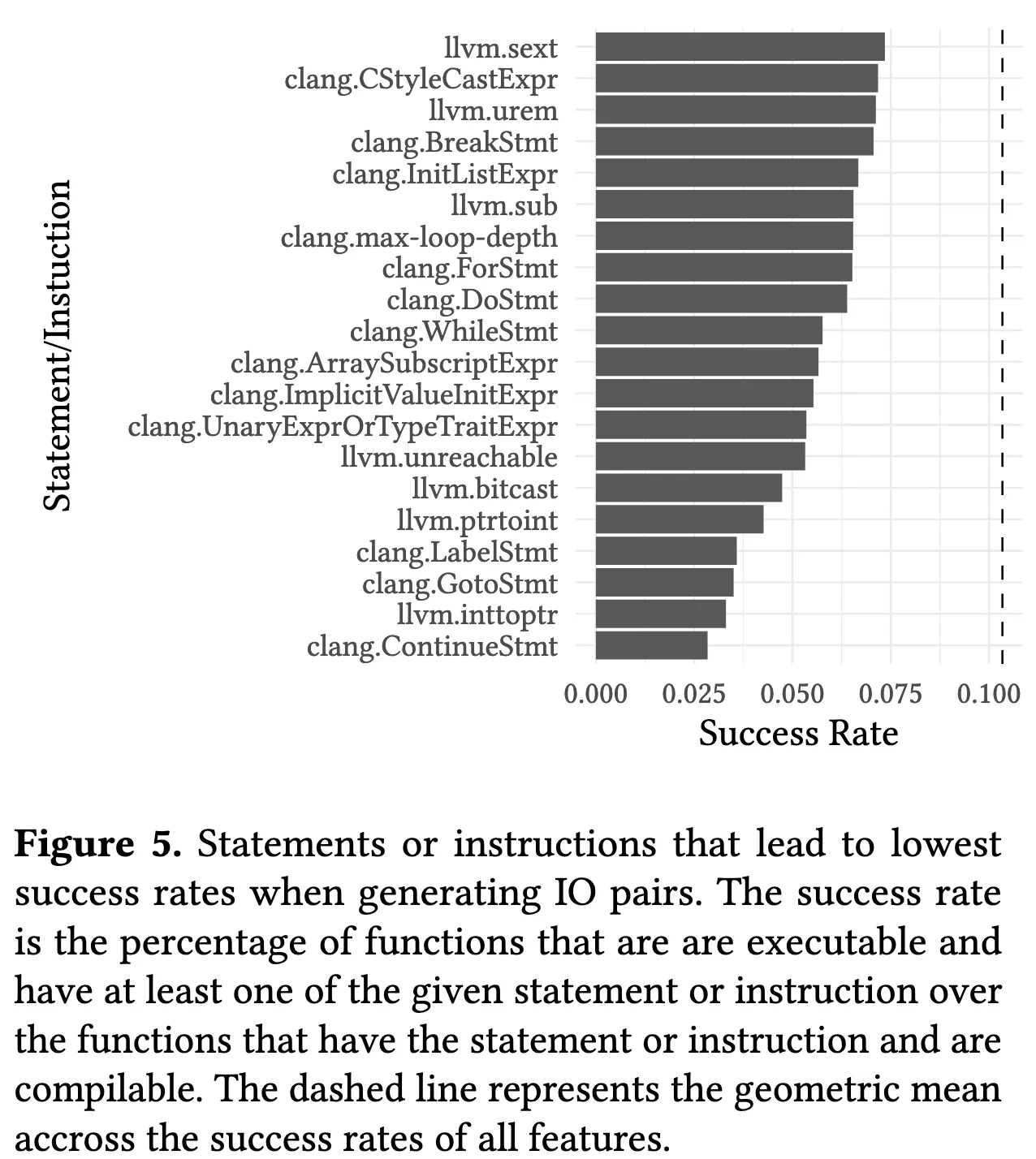
为 C 语言函数生成有效的输入数据对于可执行代码数据集至关重要。这一领域涉及多种方法,包括基于 SMT(Satisfiability Modulo Theories)[37, 38] 和符号执行(Symbolic Execution)[39] 的技术。此外,随机测试生成(Random Test Generation)技术也被用于实现相同的目标[40]。但SMT 方法通常计算开销较高,导致运行速度过慢,而其他方法则依赖于外部提供输入数据的规格说明,从而限制了其适用性。本研究提出了一种自动化且可扩展的输入数据生成方法,该方法能够高效地在大规模数据集上执行测试生成,不仅具备较强的适应性,还能有效发现某些常见错误[41, 42],并对生成代码的性能进行评估。
工作流程

上图是作者制作数据集的过程: - 宏展开(Expand Macros):但是除 include 文件
- 提取代码定义:
- 提取真实定义,提取真实的外部类型和函数定义,确保代码可以正确编译
- 注入合成定义:对于找不到的依赖项,使用合成定义替代,以保证代码片段的完整性
- 提取目标函数定义:提取当前处理的目标函数,确保后续的可执行性和数据分析
- 提取元数据:记录与该函数相关的元数据信息,例如函数的输入/输出类型、代码上下文等
- 生成 I/O:

结果
这才是想重点讲的内容,主要看怎么对比和实验的。
作者主要和 AnghaBench 和 Github 提取的内容对比。
代表性分析
作者选了几个比较有意思的指标: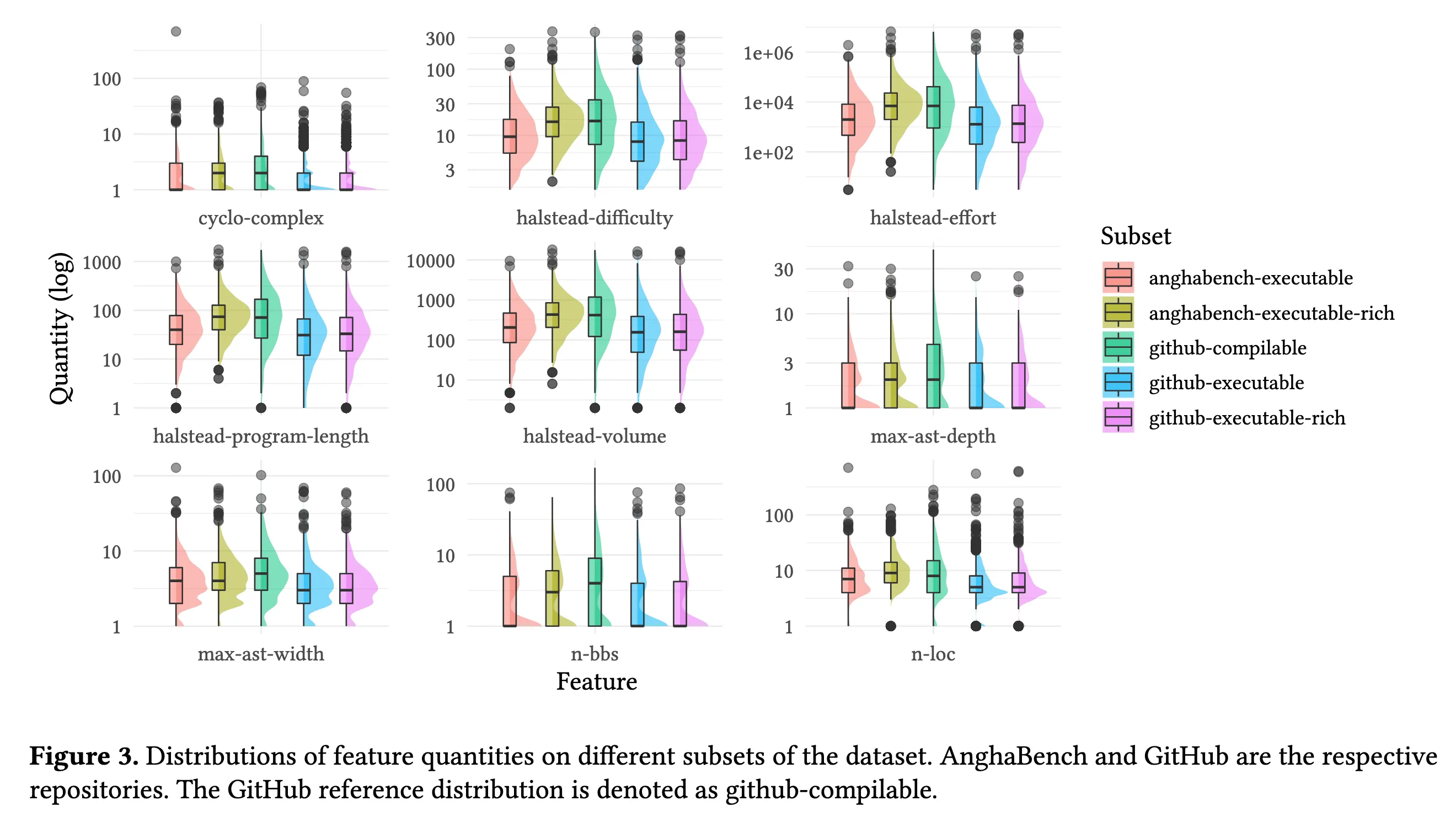
- 圈复杂度(左上):衡量程序中线性独立路径的数量
- Halstead 复杂度(中上、右上、左中、中):评估程序的开发工作量
- 代码行数
- AST 最大宽度(左下)
- AST 最大深度(右中)
- LLVM IR 未优化的基本块数量(中下)==我猜测这个是为了剔除简单函数(毕竟太简单没啥好优化的)==
代码嵌入的分布&可编译与可执行分布
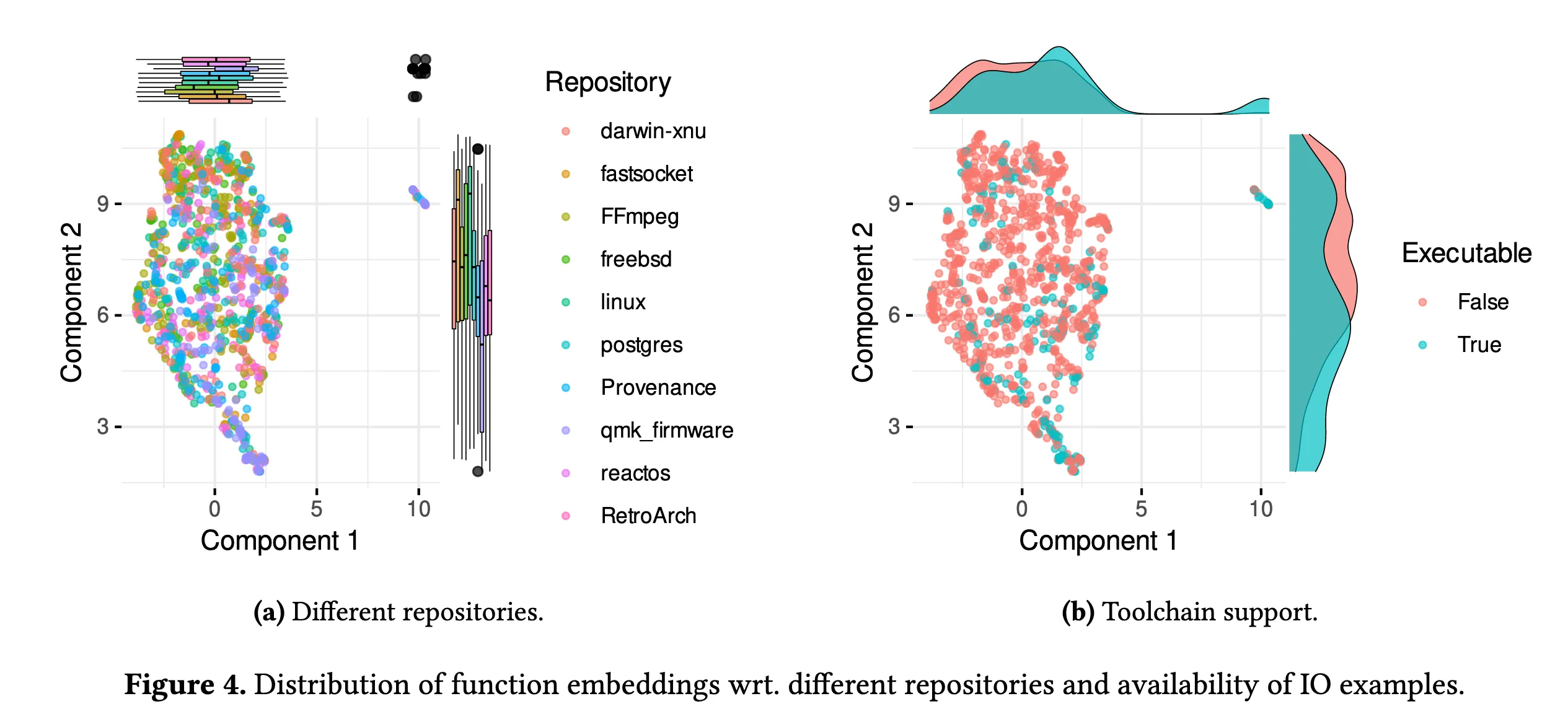
作者使用 InferCode 生成代码嵌入,并使用 UMAP 降维算法来可视化。
这个图(a)的意思是许多代码仓库在嵌入空间中具有相似的特征分布。某些项目在特征空间中的分布显著不同,如 FFmpeg 和 qmk-firmware
图 (b) 的意思是可执行是可编译的子集。错误分析
重复性分析
其他
还有数据划分、数据字段、数据集可用性、应用场景等细节