
CGO2025
杰出论文
Synthesis of Sorting Kernels
Tensorize: Fast Synthesis of Tensor Programs from Legacy Code using Symbolic Tracing, Sketching and Solving
Enhancing Deployment-Time Predictive Model Robustness for Code Analysis and Optimization
优化与变型
SySTeC: A Symmetric Sparse Tensor Compiler
Pattern Matching in AI Compilers and Its Formalization
Scalar Interpolation: A Better Balance between Vector and Scalar Execution for SuperScalar Architectures
PreFix: Optimizing the Performance of Heap-Intensive Applications
A Priori Loop Nest Normalization: Automatic Loop Scheduling in Complex Applications
An Efficient Polynomial Multiplication Derived Implementation of Convolution in Neural Networks
Postie: Extending Post-increment Addressing for Loop Optimization and Code Size Reduction
Towards Efficient Compiler Auto-tuning: Leveraging Synergistic Search Spaces
Stardust: Compiling Sparse Tensor Algebra to a Reconfigurable Dataflow Architecture
Vectron: A Dynamic Programming Auto-vectorization Framework
机器学习工具及其优化
VEGA: Automatically Generating Compiler Backends using a Pre-trained Transformer Model
IntelliGen: Instruction-Level Auto-tuning for Tensor Program with Monotonic Memory Optimization
GraalNN: Context-Sensitive Static Profiling with Graph Neural Networks
TL; DR
本文主要介绍了一个框架,其利用 GNN 来增强编译器中间表示的静态信息,通过把调用图来决定内联的方法,在真实场景上提高了 3.7%的性能。
本文细节
背景:
- PGO、BOLT 已经能大幅提升性能
- PGO 受限于动态 profile 限制(有参考文献)
- PGO 受限于动态的输入输出对,MySQL 等就不采用 PGO 技术
- 静态分析基于启发式和开发者直觉,不如现在新兴的 ML 模型
- 现有 SOTA 模型基于 XGBoost,但是
- 未利用好 IR
- 没利用好调用上下文信息
- 受限于单个函数,没有广泛的调用上下文作为模型训练(人话:没在 Module 层面考虑,而是仅仅在 Function)
贡献
- 用于 GraalVM 的基于GNN 的静态预测
- 减少了启发式的人工干预
- 引入了上下文敏感的技术来静态分析
- 在代码体积、运行时间都超过了现有 SOTA
说实话,其下游作用仅仅是为了 inline,也没说别的什么高大上的场景,比如分支预测。
作者目的是用相对较少的信息进行高质量的静态分析,因此:
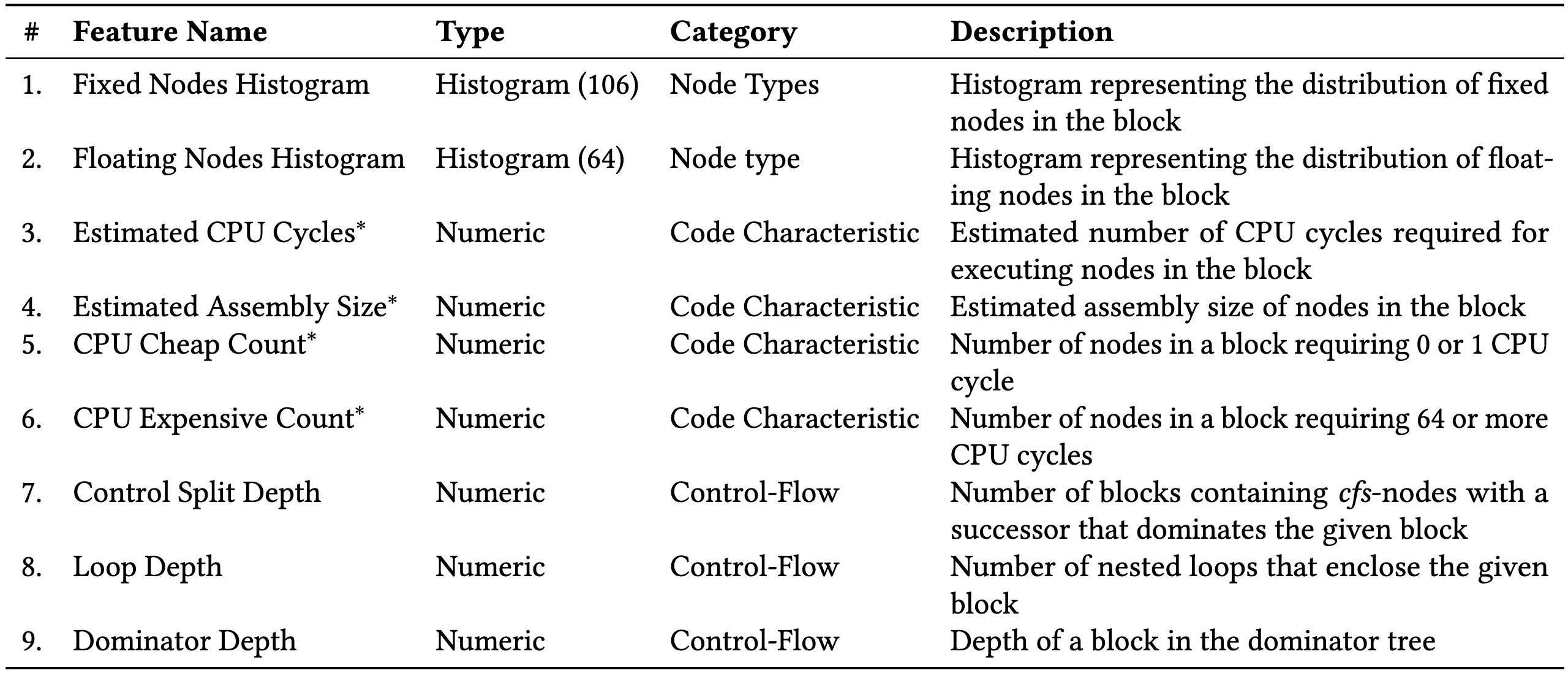
- 输入:CFGs,CFG 中提取的特征,如固定节点信息、浮动节点信息、CPU 周期、汇编体积。

- 同时还会输入边矩阵,用于表示谁调用了谁
- 还会进行分支预测

总的来说,本文不适合深入阅读,其在 Graal 上而不是通用编译器上进行测试。而且,第二第三章完全介绍了如何训练和推理,输入输出,非常得工程化,但在技术实践上可以作为参考资料,是一个通用的技术。
LLM-Vectorizer: LLM-Based Verified Loop Vectorizer
体系结构与代码生成
Calibro: Compilation-Assisted Linking-Time Binary Code Outlining for Code Size Reduction in Android Applications
TL;DR
作者为了减小移动设备上 OAT 文件的代码体积,在编译时和链接时设置了一个框架来提取相同代码,平均减少 15%的代码体积。
本文细节
- Google Play 要求软件压缩后代码体积不到 200M
- 软件大让用户不想下载
- 安卓编译器相对于 LLVM 和 GCC 不注重代码体积的优化:平均有 25%的代码冗余。
- 现有工作只在 LLVM 和 iOS 上做,没有在安卓上做。
- CodeOutling 的副作用是程序运行效率下降
- 作者收集了重要信息,能在链接时辅助优化。
- 作者使用平行后缀树减小了执行时间(不过应该是炒冷饭)
- 只降低了 1%的性能
- 本文背景:
- Code Outlining
- Code Redundancy Detection:使用后缀树搜索重复片段
- Code Redundancy Elimination
- 后缀树指式某片段出现了的次数
- 大部分重复片段较小,且基本为安卓运行时
- 作者提议用 Cache 来存储重复片段
点评:
作者花了大把时间介绍后缀树,这并不是难的知识。
作者优先把冗余代码实验做了,证明可以优化代码体积,这是体系结构的常见试验方法。
A Multi-level Compiler Backend for Accelerated Micro-kernels Targeting RISC-V ISA Extensions
xDSL: Sidekick Compilation for SSA-Based Compilers
机器学习编译器
ANT-ACE: An FHE Compiler Framework for Automating Neural Network Inference
CUrator: An Efficient LLM Execution Engine with Optimized Integration of CUDA Libraries
Accelerating LLMs using an Efficient GEMM Library and Target-Aware Optimizations on Real-World PIM Devices
MLIR
The MLIR Transform Dialect: Your Compiler Is More Powerful Than You Think
Combining MLIR Dialects with Domain-Specific Architecture for Efficient Regular Expression Matching
DialEgg: Dialect-Agnostic MLIR Optimizer using Equality Saturation with Egglog
量子计算
Synthesis of Quantum Simulators by Compilation
Weaver: A Retargetable Compiler Framework for FPQA Quantum Architectures
ASDF: A Compiler for Qwerty, a Basis-Oriented Quantum Programming Language
Qubit Movement-Optimized Program Generation on Zoned Neutral Atom Processors
程序分析与综合
Automatic Synthesis of Specialized Hash Functions
Stack Filtering: Elevating Precision and Efficiency in Rust Pointer Analysis
SkipFlow: Improving the Precision of Points-to Analysis using Primitive Values and Predicate Edges
安全与恢复力
FastFlip: Compositional SDC Resiliency Analysis
MTE4JNI: A Memory Tagging Method to Protect Java Heap Memory from Illicit Native Code Access
Memory Safety Instrumentations in Practice: Usability, Performance, and Security Guarantees
GPU 及其并行
Code Generation for Cryptographic Kernels using Multi-word Modular Arithmetic on GPU
CuAsRML: Optimizing GPU SASS Schedules via Deep Reinforcement Learning
Proteus: Portable Runtime Optimization of GPU Kernel Execution with Just-in-Time Compilation
安全、容错与密码学
Qiwu: Exploiting Ciphertext-Level SIMD Parallelism in Homomorphic Encryption Programs
Cage: Hardware-Accelerated Safe WebAssembly
Teapot: Efficiently Uncovering Spectre Gadgets in COTS Binaries
Janitizer: Rethinking Binary Tools for Practical and Comprehensive Security
Parallaft: Runtime-Based CPU Fault Tolerance via Heterogeneous Parallelism
运行时和系统工具
Honey Potion: An eBPF Backend for Elixir
GoFree: Reducing Garbage Collection via Compiler-Inserted Freeing
Improving Write-Heavy Startup Performance
Speeding up the Local C++ Development Cycle with Header Substitution
评论