
DataRecipe — How to Cook the Data for CodeLLM?
摘要 尽管语言模型的数量迅速增长,但关于训练数据集的透明性仍然不足。安全性问题常被用作解释原因,但识别高质量的训练数据对于实现模型的最优性能至关重要。然而,尽管在提升模型性能方面已付出大量努力,数据集质量这一领域仍未得到充分研究。本研究通过全面分析用于训练代码生成模型的数据质量属性和处理策略,填补这一研究空白。我们重点关注影响模型性能的数据集特性,并利用这些洞见优化数据集以提升模型效能。我们的方法涉及多方面的分析,包括元数据、统计特性、数据质量问题、意图与代码之间的语义相关性以及设计选择。通过操控这些特性,我们探讨其对模型性能的影响。研究结果表明,数据集的设计选择对代码生成模型的性能具有显著影响。此外,意图与代码之间的语义相关性也会影响性能,但其作用程度因情况而异。
INTRODUCTION
近年来,代码大型语言模型(CodeLLMs)的发展显著提升了自动化代码相关任务的能力 [15, 20, 81]。它们不仅在代码生成中发挥了关键作用,还广泛应用于许多软件工程任务中。例如,CodeLLMs可以支持软件开发流程 [86] 和调试技术 [74]。然而,这些模型的有效性往往高度依赖于用于训练的数据集质量 [6]。低质量数据集(如代码格式不一致、注释不完整或存在错误、编码模式缺乏多样性)可能导致模型的鲁棒性降低,生成的代码不准确或不优化。随着这些模型逐渐融入关键的软件工程工作流,对高质量、可靠数据集的需求变得尤为重要。
然而,目前尚未明确如何处理CodeLLMs所需的数据集。尤其是,对于ChatGPT系列 [52] 和Claude [8] 等闭源模型的数据集处理方法,并未公开以在市场竞争中获得优势。不幸的是,如果没有严格的数据集编译和预处理标准,CodeLLMs在软件实践变革中的潜力将无法充分实现。
现有的基准研究仅专注于评估和比较CodeLLMs,而未分析数据集对模型性能的影响。一些研究者已经对代码相关任务(如代码搜索 [71]、代码审查 [41, 76] 和代码理解 [46])建立了基准。这些数据集主要从高质量的GitHub代码库(通常具有大量的Stars和活跃的开发者参与度)或活跃的编码社区(如StackOverflow)中精心挑选而来。尽管现有研究内容详实具体,但它们并未深入探讨数据集特性如何影响模型性能。
有论文发现使用高Star反而训练的效果差
本研究旨在系统性评估用于训练CodeLLMs的数据集特性对模型性能的影响,特别关注文本到代码生成任务。我们首先通过零样本实验建立基线性能,随后对多个代码生成数据集进行微调,以确定哪些数据集能够最有效地提升模型性能。
在展示可能影响模型性能的特性(包括元数据、统计数据、静态分析结果、语义相关性以及设计选择)后,我们进一步尝试通过数据集修订来提升模型性能。修订过程按照三种粒度级别进行:代码级,通过自动化工具优化源代码;对级,通过增强文本提示与代码之间的语义相关性;数据集级,通过标准化数据集设计来改进。这种细化的方法允许针对性地提升数据集质量,并期望缩小数据集质量与模型实际效用之间的差距。
为实现研究目标,我们提出以下三个研究问题:
- RQ1: 数据集上的代码级自动化重构能否提升模型性能?
- RQ2: 数据集上改进对级语义相关性对模型性能有何影响?
- RQ3: 数据集的设计对齐是否能够显著提升模型性能?
实验结果揭示了以下几个重要洞见: - 数据集的影响因模型规模而异,导致在不同基准测试中的表现存在差异。
- 每个数据集都呈现出独特的统计特性,包括标记数量、代码行数、可读性、代码相关问题,以及特有的语义相关性和数据设计选择。
- 自动化重构有潜力提升代码质量,对模型性能的影响取决于模型和基准的特性,但影响程度差异较大。
- 修正语义相关性通常能够提升以功能为重点的基准测试上的性能,尽管提升幅度有限,并且对以对齐为重点的基准测试表现出中性影响。
- 数据集设计可能是性能提升的主要考虑因素,因为它在所有模型-基准组合中持续且显著地提高了性能。
BACKGROUND AND MOTIVATION
有效的代码生成模型根本上依赖于训练数据集的质量及其结构化设计。本节概述了专门为这些模型设计的数据集的关键因素和评估指标。
2.1 用于代码生成的数据集
源代码数据集被用于训练语言模型,为其提供丰富多样的示例,帮助模型掌握上下文和编码细节。数据集通常包含以下几个方面:意图、代码片段、测试用例以及元数据。
- 意图 是一种简明的描述或具体问题,采用自然语言形式,用于引导语言模型理解所需的代码生成类型。它涵盖了多个领域,如数据操作和算法问题解决。
- 代码片段 应当在语法和功能上都正确,能够代表给定文本的实际实现。这些片段的抽象程度可以从方法、类到完整项目有所不同。
- 测试用例 对于评估语言模型的代码生成能力至关重要,确保生成的代码不仅能够编译,还能够正确执行,并满足提示所要求的功能。
- 元数据 提供了补充信息,虽然与训练或评估并非直接相关,但有助于管理和理解数据集。
2.2 代码生成数据集的质量
在训练语言模型(特别是针对代码生成任务的模型)时,确保数据质量至关重要。尽管其重要性显而易见,但关于数据质量的普遍接受的定义仍未达成共识,也没有一套标准化的准则用于识别适合训练此类模型的高质量数据集 [60]。
然而,诸如利用人工注释和启发式方法等现有方法,通常用于评估数据集中各组成部分(如自然语言意图和源代码)的质量。尽管自动化质量评估技术取得了进展,但整体数据质量的验证仍然严重依赖分析人员的专业知识和直觉,尤其是在像Google这样的大型技术公司 [60]。
在自然语言处理领域,研究者通常采用多种指标和技术来衡量文本的质量,包括连贯性 [50]、流畅性 [55] 和语义相关性 [89]。相比之下,评估源代码质量涉及不同的方法,如代码简洁性度量 [70]、静态代码分析 [54]、代码审查 [32] 和单元测试 [25]。实证研究 [24, 28, 53] 表明,诸如错误、代码异味和软件复杂性等因素显著影响程序的稳定性和行为表现。
STUDY DESIGN AND PRELIMINARIES
在本节中,我们首先通过形式化定义阐述目标任务的基本原理,并讨论训练和测试数据集的选择(第3.1节),随后详细介绍语言模型的选择(第3.2节)。接着,我们说明如何评估模型性能(第3.3节),并提供实现细节(第3.4节)。此外,我们通过全参数微调探索哪些数据集能够最有效地优化现有模型的性能(第3.5节)。最后,我们总结本节,概述本文所探讨的研究问题(第3.7节)。
3.1 目标任务、训练和测试数据集
我们聚焦于代码生成任务,即根据给定的输入规范或上下文自动生成源代码工件。选择该任务作为研究目标的原因如下:
- 随着大型语言模型(LLMs)的发展,代码生成引起了广泛关注 [15, 16, 52, 68]。
- 代码生成产生可执行代码,可通过正确性 [15, 34]、语法准确性 [62] 和语义相关性 [55, 62] 等指标进行直观评估。
- 代码生成模型需要多样化的代码片段和自然语言输入对,突显了跨领域和风格的数据质量的重要性 [15]。
- 作为软件开发的重要组成部分,代码生成可以改进代码合成和文档化等实践,使数据质量研究与实际改进紧密结合 [20]。
形式化地,对于具有参数 的语言模型 和语料 ,其优化的语言建模损失定义为:
模型将提示和标准答案的拼接作为输入,并以自回归方式预测每个标记 ,基于先前的标记 。
我们选择的目标数据集基于其在代码生成领域的广泛应用。这些数据集由意图-代码对组成,对训练语言模型理解和生成编程代码至关重要。具体而言,我们采用以下数据集:
- MBPPtrain [9]:此数据集用于训练和评估代码生成模型,包括374个训练实例和500个测试实例,涵盖了基础编程概念的多样化意图-代码对。其被广泛使用的原因在于其系统性地覆盖了编程技能的核心内容。
- CoNaLatrain [87]:此数据集因其独特的组成和来源对研究者和实践者具有重要价值。它包含从StackOverflow精心收集的2,880对指令和代码片段,其中2,380个用于训练,500个用于测试,反映了开发者在多领域中的实际编程挑战与解决方案。
- CodeAlpacatrain [14]:此数据集包含2,190个编程问题及其对应解决方案,为探索自然语言理解与软件工程的交汇提供了独特机会。与CoNaLa相比,该数据集示例更长、更复杂,可更全面地评估模型的代码生成能力。
- DS-1000train [35]:这是一个专门针对代码生成的基准数据集,包括897个数据科学问题,覆盖7个Python库的多样化实际应用场景。为了避免记忆效应,该数据集对问题陈述进行了扰动。尽管其主要用于测试,但我们将其纳入目标数据集以最大化多样性。
- ODEXtrain [78]:这是一个面向文本到代码生成的开放领域、多语言、基于执行的数据集。我们仅使用439对英文文本与源代码对,涵盖从StackOverflow中提取的45个独特库,反映了实际编码查询。
值得注意的是,MBPP、CoNaLa、CodeAlpaca和ODEX数据集分别包含训练和测试部分。我们仅针对每个数据集的训练部分,但使用了DS-1000的全部内容。
实验设计与评价
为在微调过程中评估数据集质量,我们的实验分为两个类别:“功能性为重点”和“对齐性为重点”,分别通过现有知名基准进行评价。在“功能性为重点”类别中,我们使用HumanEvaltest [15, 43] 和MBPPtest [9, 43] 数据集来评估模型的功能性效果。这些是最知名的基准,我们仅使用其测试集进行基准测试。在“对齐性为重点”类别中,我们使用ODEXtest [78] 和CoNaLatest [87] 数据集来检查生成代码与目标规范的语义对齐性。为了避免数据泄漏,我们明确区分了训练数据集和上述基准测试数据集。
功能性指的是生成的代码在实际运行中的正确性和有效性;对齐性指的是生成代码与自然语言描述(即输入提示)的语义一致性,主要评估模型是否准确理解并反映了用户的意图
目标语言模型
为进行全面分析,我们选择语言模型(LMs)的标准包括以下几个方面:首先,我们仅关注开源模型,排除如ChatGPT和Codex等闭源模型,因为无法获取其参数。其次,我们选择了最近几年发布的模型。最后,为了研究模型规模的影响,我们选择了参数规模多样的模型。参数少于20亿的模型被归类为普通规模的LM,而参数超过此阈值的模型被归类为大型语言模型(LLMs)。总共,我们的实验包含来自不同模型家族的七个模型,以确保对模型性能进行全面且具有代表性的探索。
普通规模的LMs:我们使用了CodeGen-350M-Mono [51]、StarCoder-1B [39]和DeepSeek-Coder-1.3B [27]作为普通规模的语言模型。CodeGen-350M-Mono是一个自回归语言模型,是CodeGen的缩小版本。StarCoder-1B结合了自然语言处理与机器学习的能力,能够高效地解释和编写代码,适合软件开发相关应用。而DeepSeek-Coder-1.3B专注于深度代码分析和搜索功能,是DeepSeek系列中参数规模最小的版本。
LLMs:我们选择了DeepSeek-Coder-6.7B [27]、MagiCoder-DS-6.7B [79]、CodeLlama-7B [63]和Llama-2-7B [75]。DeepSeek-Coder-6.7B基于其前代模型DeepSeek的增强版本,擅长理解和优化用户特定的编码模式与偏好。MagiCoder-DS-6.7B以在广泛的编程环境和语言中的无缝集成与适应性而闻名。CodeLlama-7B是基于Llama-2-7B开发的一系列LLMs的成员。
3.3 评估指标
我们使用Pass@1 [15, 34]和BLEU [55]作为评估指标,分别提供了关于生成代码的准确性和语言质量的定量见解。
- Pass@1:衡量模型在第一次生成代码时的正确率,反映其对用户需求的理解和实现精度。
- BLEU:最初为评估机器翻译文本质量而开发,此处被用于评估生成的代码注释和文档的语法与语义连贯性。
虽然Pass@1对于评估生成代码的功能性非常有价值,但它可能无法像BLEU那样有效捕捉从自然语言描述到代码生成中的细微质量差异。
3.4 实现细节
在七个目标模型的所有训练和推理活动中,我们使用了四块NVIDIA A800 SXM4 80GB GPU。我们的研究仅关注全参数微调,以精确衡量不同数据集的影响。其他技术(如上下文学习 [11]、少样本学习 [33] 或参数高效微调 [29])可能引入潜在偏差,因此我们在本研究中避免使用。
以下是我们的超参数设置:学习率配置为,优化器采用Adafactor [66],并对所有模型使用32位浮点精度。权重衰减参数设置为0.01。在训练配置方面,最大标记长度为512,批量大小为4,梯度累积步数为8,预热步数为500。此外,我们设置了评估间隔,使得每次模型评估之间能覆盖0.2比例的样本。在推理阶段,我们选择最低评估损失的检查点,训练轮数设为50,以优化准确性并确保性能最大化。
为促进后续研究与结果复现,我们已将代码和数据公开 [1]。
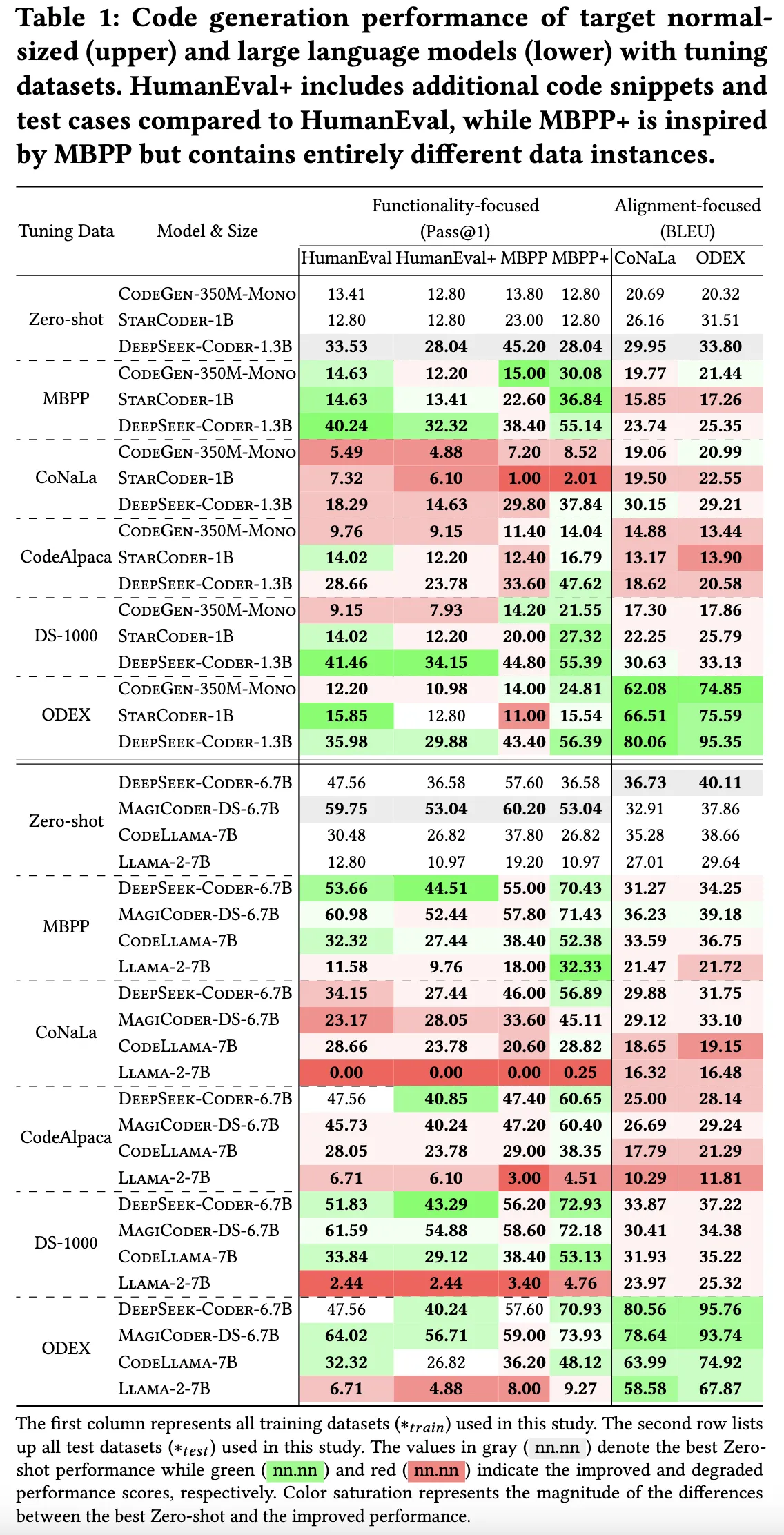
3.5 基线性能探索
本节旨在通过微调模型评估不同数据集对模型性能的影响。为开展这一评估,我们首先确立各模型的零样本(Zero-shot)性能作为基线,然后在保持所有超参数和实验环境一致的条件下,使用每个数据集对模型进行微调。这一严格的设置确保了观察到的性能差异可以完全归因于数据集的影响。
表1展示了所有模型在目标数据集上的全面代码生成性能。如第3.3节所述,我们使用两种不同的性能指标:功能性为重点的指标(Pass@1) 和 对齐性为重点的指标(BLEU)。我们在一致的超参数和实验条件下对模型进行微调,并通过性能评估与零样本基线进行对比。这种严谨的方法确保了性能变化仅反映数据集对模型性能的影响。
结果与分析:
- 零样本性能:
表中用灰色单元格标出了最佳零样本性能。整体来看,DeepSeek-Coder-1.3B在普通规模的语言模型中表现最佳,而MagiCoder-DS-6.7B在大型语言模型类别中表现领先。 - 微调性能:
表中用颜色标注了微调后性能的变化:绿色单元格表示性能提升,红色单元格表示性能下降。不同数据集在两个性能指标上的表现差异表明,每个指标的最佳微调数据集是不同的,并且受模型规模的影响。
关键发现:
- 对普通规模语言模型的影响:
- 在Pass@1指标上,MBPPtrain 是微调普通规模语言模型的最有效数据集,显著提升了其功能性表现。
- 对大型语言模型的影响:
- 在大型语言模型中,DS-1000train 是在Pass@1指标上提升性能的最优数据集,为LLMs提供了最大的性能增益。
- 对基准测试的影响:
- ODEXtrain 数据集对CoNaLatest和ODEXtest基准的影响最为显著,是对齐性为重点评估的最具影响力的微调数据集。
总体而言,微调不同数据集对代码生成性能的影响是显著的,不同数据集在不同的指标和模型规模上表现出独特的优势。这表明数据集的选择对优化模型性能具有关键作用,并且应针对具体的指标和模型类型进行选择。有关键作用,并且应针对具体的指标和模型类型进行选择。有关键作用,并且应针对具体的指标和模型类型进行选择。
- ODEXtrain 数据集对CoNaLatest和ODEXtest基准的影响最为显著,是对齐性为重点评估的最具影响力的微调数据集。