
Machine Learning in Compiler Optimization
Machine Learning in Compiler Optimization
Abstract
在过去十年中,基于机器学习的编译技术已经从一个鲜为人知的研究领域发展成为主流活动。本文描述了机器学习与编译优化之间的关系,并介绍了特征、模型、训练和部署等主要概念。接着,我们提供了一个全面的综述,并为这一领域的众多研究方向提供了路线图。最后,本文讨论了该领域中的开放性问题以及潜在的研究方向。本论文既为快速发展的基于机器学习的编译领域提供了一个易于理解的介绍,又提供了该领域主要成就的详细参考文献。
Introduction
“为什么有人会想使用机器学习来构建编译器?”
这是过去十年中许多同行所表达的观点。编译器将人类编写的编程语言翻译为计算机硬件可执行的二进制代码。这是一个自1950年代以来便受到严谨研究的课题[1]–[3],其正确性至关重要,谨慎是其一贯特征。另一方面,机器学习是人工智能(AI)领域的一个分支,旨在识别和预测模式。它是一个动态发展的领域,涵盖了从星系分类[4]到基于推特信息预测选举[5]等多种主题。2009年,当IBM宣布发布开源机器学习编译器时[6],一些在Slashdot上的评论者戏谑地关注了AI这一方面,预测这将标志着意识计算机、全球网络以及《终结者》电影系列中与机器的战争的开始。
事实上,正如本文所展示的,编译器与机器学习是天然契合的,并且已经发展成为一个成熟的研究领域。
A. It Is All About Optimization
编译器有两个任务——翻译和优化。首先,它们必须正确地将程序翻译成二进制代码。其次,它们需要找到最有效的翻译方式。存在许多不同的正确翻译,其性能差异显著。绝大多数的研究和工程实践集中在第二个目标——性能,传统上被误称为优化。之所以被误称,是因为在大多数情况下,直到最近,寻找最优翻译被认为过于困难且不切实际。因此,研究重点转向开发编译器启发式方法,通过变换代码以期提高性能,尽管在某些情况下,这些方法反而可能损害性能。
机器学习根据先前的数据预测新数据点的结果。在其最简单的形式下,机器学习可以被视为一种插值方法。基于先前信息进行预测的能力可以用来找到具有最佳结果的数据点,这与优化领域密切相关。正是在将代码改进视为优化问题,而将机器学习视为最优解预测工具的交汇处,我们发现了机器学习编译的应用。
优化作为一个研究领域,无论是基于机器学习的还是其他形式的,自19世纪以来便已得到研究[8],[9]。因此,一个有趣的问题是,为什么这两个领域的融合会花费如此长的时间?其中有两个根本原因。
- 首先,尽管硬件的潜在性能逐年提升,软件却越来越无法充分发挥其潜力,导致了所谓的软件差距。这一差距随着多核处理器的出现而愈加显著(参见第VI-B节)。编译器开发者正在寻找新的方法来弥合这一差距。
- 其次,计算机体系结构的演进速度极快,难以跟上。每一代体系结构都有新的特性,编译器开发者总是在努力追赶。机器学习具有自动化的优点。与其依赖专家编译器开发者设计巧妙的启发式方法来优化代码,不如让机器学习如何优化编译器以提高机器运行速度,这种方法有时被称为自动调优[10]–[13]。
因此,机器学习非常适合用于做出任何依赖于底层平台的性能影响的代码优化决策。正如本文后续所描述的,它可以应用于多个领域,从选择最佳的编译器标志到确定如何将并行性映射到处理器。
机器学习是计算机科学和编译领域中日益自动化传统的一部分。从1950年代到1970年代,研究主要集中在尝试自动化编译器翻译,例如,使用lex进行词法分析[14]和使用yacc进行语法解析[15];相比之下,过去十年的研究则集中在尝试自动化编译器优化。如我们所见,机器学习并非“魔法”或编译器开发者的万能法宝,而是另一种工具,能够自动化编译过程中繁琐的环节,并为创新提供新的机会。它还将编译工作推进到基于证据的科学标准。机器学习引入了一种实验性方法论,其中我们将评估与设计分离,并考虑解决方案的鲁棒性。基于机器学习的方案通常存在依赖黑箱的难题,我们无法理解其工作原理,因此难以信任。这一问题同样适用于基于机器学习的编译器。在本文中,我们旨在揭开基于机器学习的编译的神秘面纱,展示其作为编译器研究的可信且令人兴奋的方向。
本文的剩余部分结构安排如下:
首先,在第二节中,我们将直观地概述机器学习在编译器中的应用。
接着,在第三节中,我们将描述机器学习如何用于搜索或直接预测优良的编译器优化。
随后,在第四节中,我们将对先前工作中使用的广泛机器学习模型进行全面讨论。
接下来,在第五节中,我们回顾先前研究中如何选择量化属性或特征来表示程序。
在第七节中,我们将讨论将机器学习应用于编译过程中的挑战和局限性,以及未来的研究方向。
最后在第八节中进行总结和结论。
Overview of Machine Learning in Compilers
对于给定的程序,编译器开发者希望知道应应用何种编译器启发式方法或优化,以使代码变得更好。“更好”通常意味着执行速度更快,但也可以指代码占用空间更小或功耗更低。机器学习可以用来构建一个模型,该模型在编译器内部用于为任何给定的程序做出此类决策。
该过程主要包括两个阶段:学习和部署。在学习阶段,根据训练数据学习模型,而在部署阶段,则使用该模型对新的未见过的程序进行处理。在学习阶段,我们需要以一种系统化的方式表示程序,这种表示方式被称为程序特征[16]。
图1直观地展示了机器学习如何应用于编译器的过程。该过程包括特征工程、模型学习和部署,具体内容将在以下各节中详细描述。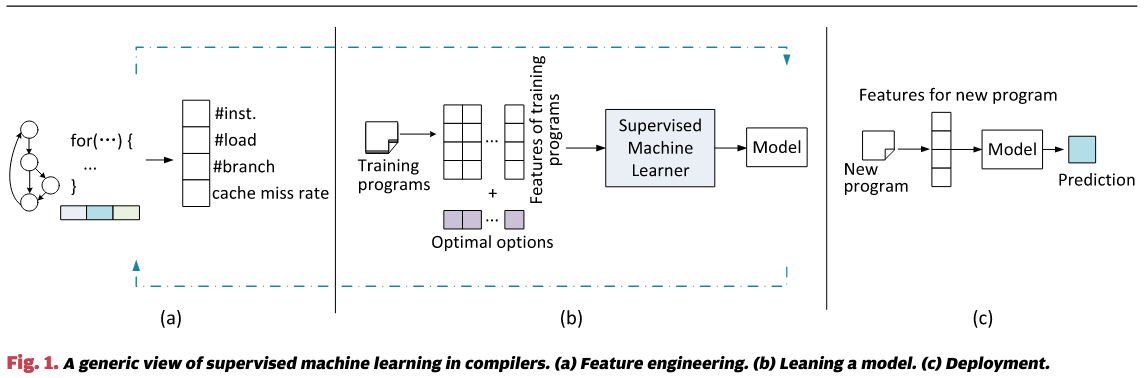
Feature Engineering
在我们能够从程序中学习任何有用的知识之前,首先需要能够对程序进行表征。机器学习依赖一组==可量化==的属性或特征来表征程序[图1(a)]。可以使用许多不同的特征,包括从程序源代码或编译器中间表示中提取的静态数据结构(如指令数或分支数)、通过运行时分析获得的动态性能信息(如性能计数器值),或两者的组合。
标准的机器学习算法通常处理固定长度的输入,因此所选的属性将被总结为一个固定长度的特征向量。该向量的每个元素可以是整数、实数或布尔值。特征选择和调优的过程被称为特征工程。为了构建一个准确的机器学习模型,这一过程可能需要反复进行多次,以找到一组高质量的特征。在第五节中,我们将提供关于程序优化主题的特征工程的全面回顾。
Learning a Model
第二步是使用训练数据通过学习算法推导出模型。此过程如图1(b)所示。与机器学习的其他应用不同,我们通常使用现有的应用程序或基准测试生成自己的训练数据。编译器开发人员会选择典型的训练程序,这些程序代表了应用领域中的典型特征。对于每个训练程序,我们计算其特征值,通过不同的优化选项编译程序,并运行和计时编译后的二进制文件,以发现最佳的性能选项。该过程为每个训练程序生成一个训练实例,该实例由特征值和该程序的最优编译选项组成。
编译器开发人员随后将这些示例输入机器学习算法,以自动构建模型。学习算法的任务是从训练示例中发现特征值与最优优化决策之间的关联。训练得到的模型可以用来预测对于一组新的特征,应该选择何种最优优化选项。
由于所学模型的性能在很大程度上依赖于特征和训练程序的选择【PROBLEM】,因此特征工程和训练数据生成的过程通常需要多次迭代才能达到最佳效果。
Deployment
在最后一步,学习到的模型被嵌入到编译器中,用于预测新程序的最佳优化决策。如图1©所示。为了进行预测,编译器首先提取输入程序的特征,然后将提取的特征值输入到已学习的模型中,以进行预测。
基于机器学习的方法的优势在于,每当编译器需要针对新的硬件架构、操作系统或应用领域进行优化时,整个构建模型的过程可以轻松重复。所构建的模型完全来源于实验结果,因此具有基于证据的特点。
Example
以线程粗化(thread coarsening)[18] 为例来说明这些步骤。线程粗化是一种针对GPU程序的代码转换技术,其原理是将多个工作项(或工作元素)分配给单个线程。它类似于循环展开,但应用于并行工作项,而非串行循环迭代。
图 2(a) 展示了一个简单的 OpenCL 内核,其中每个线程一次操作输入数组 in 中的一个工作项。要操作的工作项由 OpenCL 的 get_global_id() API 返回的值指定。图 2(b) 显示了应用线程粗化因子为 2 后转换的代码,其中每个线程处理输入数组中的两个元素。

线程粗化可以通过增加指令级并行性 [19]、减少内存访问操作的次数 [20],以及消除当每个工作项计算相同值时的冗余计算来提升性能。然而,它也可能带来一些负面副作用,例如减少总体并行性并增加寄存器压力,这可能导致性能下降。确定何时以及如何应用线程粗化并非易事,因为最佳的粗化因子依赖于目标程序以及程序运行所在的硬件架构 [17], [19]。
Magni 等人表明,机器学习技术可以用于自动构建跨 GPU 架构的有效线程粗化启发式方法 [17]。他们的方法考虑了六个粗化因子(1, 2, 4, 8, 16, 32)。其目标是开发一个基于机器学习的模型,以决定是否在特定的 GPU 架构上进行 OpenCL 内核的粗化,如果是,最佳的粗化因子是什么。在众多机器学习算法中,他们选择使用人工神经网络来建模该问题。构建这样的模型遵循经典的三步监督学习过程,如图 1 所示,并在以下部分做了更详细的描述。
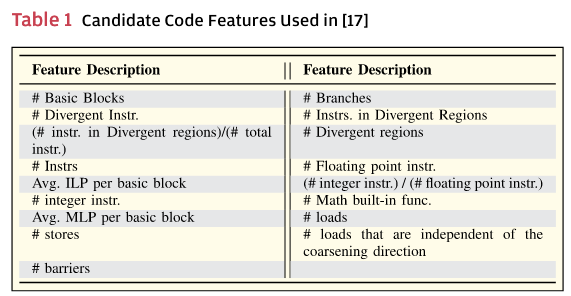
- 特征工程:为了描述输入的 OpenCL 内核,Magni 等人使用从编译器的中间表示中提取的静态代码特征。具体而言,他们开发了一种基于编译器的工具,用于从程序的 LLVM BitCode [21] 中获取特征值。他们从 17 个候选特征开始,这些特征包括 OpenCL 内核中指令的数量和类型以及内存级并行性(MLP)等。表 1 给出了 [17] 中使用的候选特征列表。通常,候选特征的选择可以基于开发人员的直觉、先前工作的建议,或者两者的结合。在选择候选特征后,采用一种名为主成分分析(PCA,见第 IV-B 节)的统计方法,将 17 个候选特征映射到七个聚合特征中,使得每个聚合特征都是原始特征的线性组合。这种技术称为“特征维度降维”,将在第 V-D2 节中讨论。维度降维有助于消除候选特征之间的冗余信息,从而使学习算法能够更有效地执行。
- 模型学习:对于 [17] 中展示的工作,使用了 16 个 OpenCL 基准测试来生成训练数据。为了找出哪一个线程合并因子在特定 GPU 架构上为给定 OpenCL 内核表现最好,我们可以将这六个因子应用于 OpenCL 内核,并记录其执行时间。由于最佳的线程合并因子在不同的硬件架构上有所不同,因此这一过程需要为每个目标架构重复进行。除了找出表现最好的合并因子外,Magni 等人还提取了每个内核的聚合特征值。在训练基准上应用这两个步骤后,生成的训练数据集中的每个训练样本由最优的合并因子和训练内核的特征值组成。然后,这些训练样本被输入到学习算法中,算法试图找到一组模型参数(或权重),使得在训练样本上的整体预测误差最小化。学习算法的输出是一个人工神经网络模型,其中其权重是通过训练数据确定的。
- 部署:然后,学习到的模型可以用于预测未见过的 OpenCL 程序的最优合并因子。为此,首先从目标 OpenCL 内核中提取静态源代码特征;然后将提取的特征值输入到模型中,模型决定是否进行线程合并,并选择应使用的合并因子。[17] 中提出的技术在四种 GPU 架构上实现了 1.11 倍至 1.33 倍的平均加速,并且在任何一个基准测试上都没有导致性能下降。

Methodology
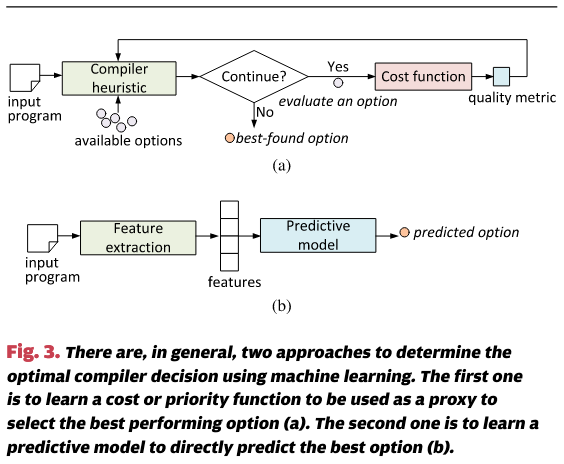
编译中的一个关键挑战是为给定程序选择合适的代码转换或转换序列。这需要有效地评估某个可能的编译选项的质量,例如,代码转换如何影响最终性能。
一种简单的方法是穷举地应用每一个合法的转换选项,然后对程序进行分析,以收集相关的性能指标。然而,考虑到许多编译问题有大量的选项,穷举搜索和分析是不可行的,这限制了该方法在大规模应用中的使用。这种基于搜索的编译优化方法被称为迭代编译[22],[23]或自动调优[10],[24]。许多技术已被提出以减少搜索大空间的成本[25],[26]。在某些情况下,如果程序需要多次使用,例如在深度嵌入式设备中,这种开销是可以接受的。然而,它的主要局限性仍然存在:它仅为一个程序找到好的优化,并且无法推广为编译器启发式方法。
解决可扩展地选择适用于多个程序的编译选项的问题,主要有两种方法。图3中给出了这两种方法的高层次比较。
第一种策略尝试开发一个成本(或优先级)函数,作为估算潜在编译决策质量的代理,而无需依赖广泛的性能分析。
第二种策略是直接预测最佳的执行选项。
Building a Cost Function
许多编译器启发式方法依赖于成本函数来估计编译选项的质量。根据优化目标,质量度量可以是执行时间、代码大小、能耗等。通过使用成本函数,编译器可以评估一系列可能的选项,从中选择最佳选项,而无需在每个选项下都进行编译和分析程序。
手工编写启发式方法的问题
传统上,编译器的成本函数是手工编写的。例如,函数内联的启发式方法会将多个相关度量值相加,如待内联目标函数的指令数、内联后的被调用者和栈大小,并将得到的值与预设阈值进行比较,以确定是否内联函数[27]。在此过程中,度量值的重要性或权重以及阈值由编译器开发人员根据经验或通过“试错法”来确定。由于调优成本函数所需的努力非常大,许多编译器仅使用“通用型”成本函数进行内联。然而,这种策略是低效的。例如,Cooper 等人表明,内联的“通用型”策略往往会导致较差的性能[28];其他研究也表明,用于决定何时进行内联的最佳阈值因程序而异[29],[30]。
手工编写的成本函数在编译器中被广泛使用。其他例子包括Wagner等人[31]和Tiwari等人[32]的工作。前者结合了马尔可夫模型和人工启发式方法,用于静态估算代码区域(如函数调用次数)的执行频率。后者通过为每种指令类型分配权重来计算应用程序的能耗。这些方法的效率高度依赖于人工调优的启发式方法所给出的估算准确性。
依赖手工调优的启发式方法的问题在于,编译器优化的成本和效益通常依赖于底层硬件;==尽管手工编写的成本函数可能是有效的,但在单一架构上手动开发一个成本函数可能需要数月或数年的时间。==这意味着,为每个新发布的处理器调优编译器是困难的,且由于所涉及的巨大工作量,往往是不可行的。由于成本函数非常重要,而为每种架构手动调优一个良好的成本函数十分困难,因此研究人员已开始探索使用机器学习来自动化这一过程。
在第III-A2节中,我们回顾了关于使用机器学习调优成本函数以优化性能和能耗的一系列先前研究——其中许多研究也可以应用于其他优化目标,如代码大小[33],或能耗与运行时之间的权衡。
性能的成本函数
Meta优化框架[34]使用遗传编程(GP)来搜索成本函数 ,该函数输入一个特征向量 ,输出一个实数值的优先级 。图4展示了该框架的工作流程。该方法在多个编译器问题上进行了评估,包括超块形成、寄存器分配和数据预取,结果表明机器学习的成本函数优于人工设计的成本函数。Cavazos等人采用了类似的方法,寻找Java即时编译器(JIT)的性能和编译开销的成本函数[35]。COLE编译器[36]使用遗传编程算法的一个变种,即强度帕累托进化算法2(SPEA2)[37],来学习成本函数以平衡多个目标(如程序运行时间、编译开销和代码大小)。在第IV-C节中,我们将描述类似遗传编程的搜索算法的工作机制。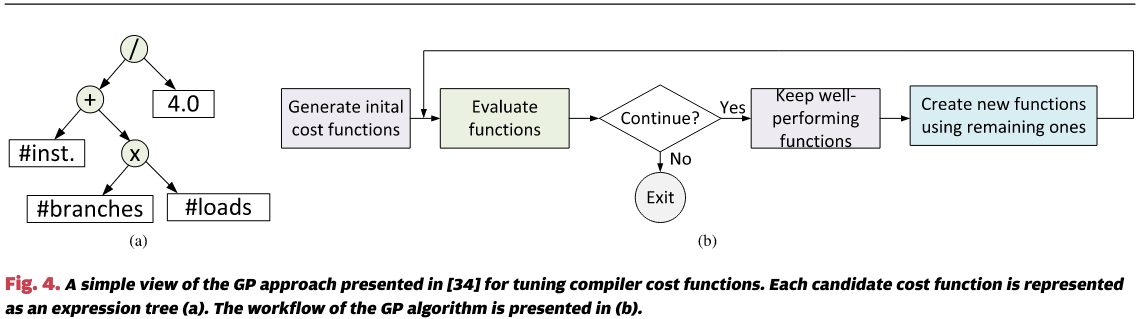
另一种调优成本函数的方法是预测目标程序的执行时间或加速比。Qilin编译器[38]采用了这种方法。它使用曲线拟合算法来估计给定输入大小在CPU和GPU上执行目标程序的运行时间。编译器随后利用这些信息来确定跨CPU和GPU的最佳循环迭代分配。Qilin编译器依赖于一个特定应用的函数,该函数基于每个程序的参考输入构建。Qilin编译器使用的曲线拟合(或回归;见第IV节)模型可以处理连续值,因此适用于估算运行时间和加速比。在[39]中,扩展了这一方法,开发了一种相对预测器,用于预测在GPU上未见过的预测器相对于CPU是否会显著改进。这用于OpenCL作业的运行时调度。
Brewer早期的研究提出了一种基于回归的模型,用于预测数据布局方案在并行化中的执行效果,该模型考虑了三个参数[40]。利用该模型,他的方法可以在四个平台上为偏微分方程(PDE)求解器选择最优布局,覆盖了超过99%的时间。其他一些早期的研究也使用了曲线拟合算法来构建成本函数,估算顺序程序[41]–[43]、OpenMP程序[44]–[46],以及最近的深度学习应用程序[47]的加速比或运行时间。
- 能耗成本函数:除了性能优化外,还有大量研究探讨了为软件优化和硬件架构设计构建能量模型的方法。由于功耗或能量读数是连续的实数值,先前的大多数功耗建模工作采用了基于回归的方法。
其他研究采用人工神经网络(ANN)自动构建功率模型。Curtis-Maury 等人开发了一种基于ANN的模型,用于预测在多核系统上运行的OpenMP程序的功耗[51]。该模型的输入是硬件性能计数器值,例如缓存未命中率,输出是估计的功耗。Su 等人采用了类似的方法,开发了一种ANN预测器,用于估算在非统一内存访问(NUMA)多核系统上映射OpenMP程序的运行时间和功耗。这种方法也基于对目标程序的运行时分析,但它明确考虑了NUMA特定的信息,如每周期的本地和远程内存访问。
线性回归是能量建模中广泛使用的技术。Benini 等人开发了一个基于线性回归的模型,用于估算指令级别的功耗[48]。Rethinagiri 等人提出的框架[49]使用参数化公式来估算嵌入式系统的功耗。这些公式的参数通过将回归算法应用于使用手工编写的汇编代码和功率测量所获得的参考数据来确定。在最近的研究中,Schürmans 等人也采用了基于回归的方法进行功率建模[50],但是回归模型的权重是通过使用标准基准测试来确定的,而不是手写的汇编程序。
Directly Predicting the Best Option
直接预测并行程序的最佳选项比顺序程序更为复杂,因为并行程序与底层并行架构之间存在复杂的交互关系。然而,已有一些研究致力于预测运行OpenMP程序时使用的最佳线程数[46], [58],为给定输入编译CUDA程序时使用的最佳参数[59],以及为GPU上的OpenCL程序选择线程粗化参数[17]。这些研究表明,监督式机器学习可以成为建模具有相对较少优化选项问题的强大工具。
尽管成本函数对于评估编译器选项的质量很有用,但搜索最优选项的开销仍然可能是不可承受的。因此,研究人员已经探索了使用机器学习直接预测最佳编译决策的方法,尤其是对于相对较小的编译问题。
Monsifrot 等人率先使用机器学习来预测最佳编译决策[16]。该研究开发了一种基于决策树的方法,旨在根据诸如循环语句数和算术运算数等信息,判断是否展开循环。他们的方法对是否展开循环做出二元决策,但没有明确指出循环应展开多少次。随后,Stephenson 和 Amarasinghe 在该研究的基础上进一步推进[16],通过考虑八种展开因子(1, 2, …, 8)来直接预测循环展开因子[52]。他们将该问题表述为一个多类分类问题(即每个循环展开因子都是一个类别)。他们使用了来自72个基准测试的2500多个循环来训练两种机器学习模型(最近邻和支持向量机(SVM)模型),以预测未见循环的展开因子。与[16]相比,他们使用了更丰富的特征集,并成功预测了65%的测试循环展开因子,平均提高了SPEC 2000基准套件5%的性能。
对于顺序程序,已有大量工作致力于预测最佳编译标志[53],[54]、代码转换选项[55],或循环的分块大小[56],[57]。这一领域的兴趣可能源于问题的限制性特征,使得实验和与先前工作的比较变得更加容易。
Machine Learning Models
在本节中,我们回顾了用于编译器优化的广泛机器学习模型。表2总结了本节讨论的机器学习模型集合。
机器学习技术在编译器优化中有两个主要的细分领域:监督学习和无监督学习。在监督学习中,预测模型基于经验性能数据(带标签的输出)和代表性程序的关键可量化属性(特征)进行训练。模型学习这些特征值与提供最佳(或近似最佳)性能的优化决策之间的相关性。学习到的相关性用于预测新程序的最佳优化决策。根据输出的性质,预测模型可以是用于连续输出的回归模型,也可以是用于离散输出的分类模型。
在另一类机器学习技术——无监督学习中,学习算法的输入仅仅是一组输入值——没有标签输出。无监督学习的一种形式是聚类,它将输入数据项分组为多个子集。例如,SimPoint [60],一种模拟技术,使用聚类来选择代表程序执行点进行程序模拟。它通过首先将一组程序运行时信息划分为若干组(或簇),使得每个簇内的点在程序结构(循环、内存使用等)上相似;然后,从每个簇中选择一些点来代表该组内的所有模拟点,而不会丢失太多信息。
还有一些技术位于监督学习和无监督学习的边界。这些技术通过在部署过程中获得的经验观察来优化在离线学习或先前运行中收集的知识。我们将在IV-C节中回顾这些技术。本节最后将讨论不同建模方法在编译器优化中的相对优缺点。
Supervised Learning
回归
回归是一种广泛使用的监督学习技术。这项技术已经被应用于各种任务,例如预测给定输入的程序执行时间[38]或加速比[39],或者估算并行工作负载的尾延迟[61]。
回归本质上是曲线拟合。例如,考虑图5,其中一个回归模型是从五个数据点中学习到的。该模型接收程序输入大小X并预测程序的执行时间Y。按照监督学习的命名法,这五个已知数据点构成了训练数据集,组成训练数据的每个数据点称为训练实例。每个训练实例(xi, yi)由特征向量(即我们的输入大小)xi和期望输出(即程序执行时间)yi定义。在这个背景下,学习被理解为发现输入(xi)和输出(yi)之间的关系,从而使预测模型能够对任何新的、未见过的输入特征做出预测。一旦函数f确定,就可以通过输入新的特征向量x来进行预测。预测y是与新输入特征向量x对应的曲线值。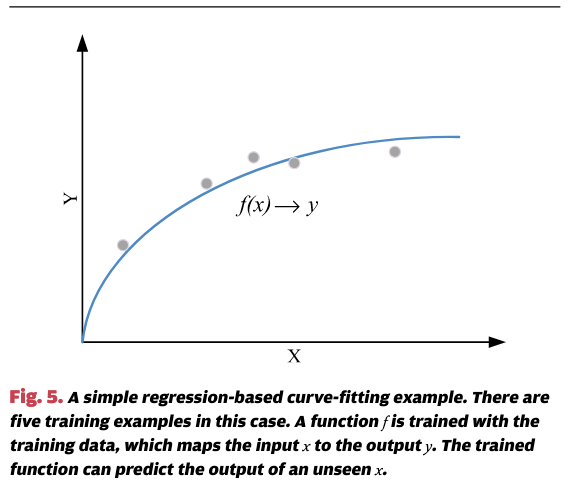
有许多机器学习技术可以用于回归。这些包括简单的线性回归模型以及更高级的模型,如支持向量机(SVM)和人工神经网络(ANN)。当输入(即特征向量)和输出(即标签)之间有强线性关系时,线性回归是有效的。支持向量机和人工神经网络可以建模线性和非线性关系,但通常需要比简单线性回归模型更多的训练实例来学习一个有效的模型。
表3给出了先前工作中用于代码优化的回归技术及其要建模的问题示例。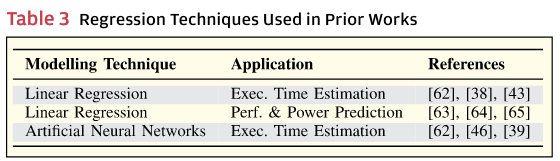
分类
监督分类是机器学习代码优化领域中广泛使用的另一种技术。==这种技术接受一个特征向量,并预测该特征向量属于一组类中的哪一类。==例如,分类可以用于预测给定循环应该使用的展开因子,通过输入一个描述目标循环特征的特征向量(参见第II-D节)。
K近邻算法 (KNN) 是一种简单而有效的分类技术。它通过在特征空间中找到与输入实例(或程序)最接近的k个训练样本来进行分类。相似度(或距离)通常使用欧几里得距离来评估,但也可以使用其他度量标准。KNN已经在之前的研究中被用来预测优化参数的最优值 [52]、[66]、[67]。它的工作原理是,首先预测哪些训练程序在特征空间中与输入程序最接近(即最近邻);然后使用在训练时找到的最近邻的最优参数作为预测输出。尽管KNN在小规模问题中非常有效,但它也有两个主要缺点。首先,每次预测时都需要计算输入与所有训练数据之间的距离,如果训练程序数量很大,计算可能会非常缓慢。其次,KNN算法本身并没有从训练数据中“学习”;它只是简单地选择k个最近邻。这意味着该算法对噪声数据不够鲁棒,可能会选择不合适的训练程序作为预测结果。
作为替代方案,决策树在之前的研究中已被广泛应用于各种优化问题。这些问题包括选择循环并行化的并行策略 [69]、确定循环展开因子 [16]、[70]、决定使用GPU加速的可行性 [68]、[71]以及选择最优的算法实现 [72]。决策树的优势在于其学习的模型是可解释的,并且可以很容易地进行可视化。这使得用户能够理解为什么做出某个决策,通过从根节点到叶子决策节点的路径来进行追溯。例如,图6展示了 [68] 中开发的决策树模型,用于选择运行OpenCL程序的最佳设备(CPU或GPU)。为了进行预测,我们从树的根节点开始;比较目标程序的特征值(例如,通信-计算比)与阈值,决定沿着树的哪个分支走;然后我们继续这个过程,直到到达叶子节点并做出决策。需要注意的是,树的结构和阈值是由机器学习算法自动确定的,当我们面向不同的架构或应用领域时,这些结构和阈值可能会发生变化。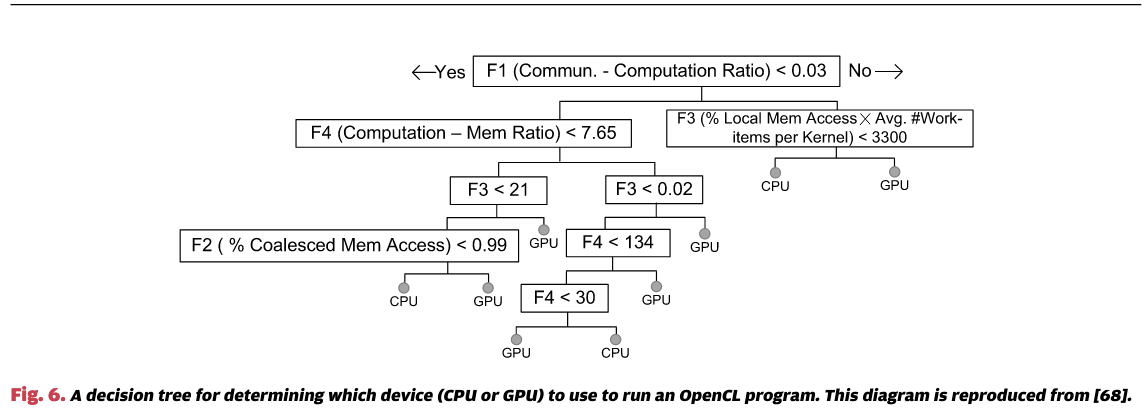
决策树假设特征空间是凸的,即可以通过超平面将其划分为不同的区域,每个区域对应于一个不同的类别。这个假设在实际应用中通常是合理的。然而,使用单一决策树的一个显著缺点是,模型可能由于训练数据中的离群点而发生过拟合(参见第IV-D节)。因此,随机森林 [73] 被提出用以缓解过拟合问题。随机森林是一种集成学习方法 [74]。如图7所示,随机森林通过在训练时构建多个决策树来工作。每棵树的预测依赖于一个在特征值上独立采样的随机向量。通过这种方式,每棵树被随机地强制对某些特征维度不敏感。为了做出预测,随机森林通过聚合各个树的结果来形成最终预测。随机森林已经被用于确定是否对一个函数进行内联 [75],并且比基于单一模型的方法提供了更好的性能。我们需要强调的是,随机森林也可以用于回归任务。例如,它曾被用于建模OpenMP [76]和CUDA [77]程序的能耗。
逻辑回归是线性回归的一个变种,但通常用于分类任务。它接受特征向量并计算某个结果的概率。例如,Cavazos和O’Boyle使用逻辑回归来确定Jike RVM的优化级别。与决策树类似,逻辑回归也假设特征值与预测结果之间存在线性关系。
更高级的模型,如支持向量机(SVM)分类,已被应用于各种编译器优化任务 [46],[79]–[81]。支持向量机通过核函数来计算特征向量之间的相似性。径向基函数(RBF)在之前的研究中被广泛使用 [46],[82],因为它能够同时建模线性和非线性问题。其原理是将输入特征向量映射到一个更高维的空间,在这个空间中,可能更容易找到一个线性超平面来有效地将标记数据(或类别)分开。
其他机器学习技术,如核典型相关分析和朴素贝叶斯,也已在之前的研究中被用于预测模板程序配置 [83] 或检测并行模式 [84]。
深度神经网络
近年来,深度神经网络(DNN)[85] 已被证明是解决一系列机器学习任务的强大工具,如图像识别 [86]、[87] 和音频处理 [88]。深度神经网络最近被用于建模程序源代码 [89],以支持各种软件工程任务(参见第VI-C节),但迄今为止,应用深度神经网络于编译器优化的研究尚不多。近期在这一方向上的尝试是DeepTune框架 [78],该框架利用深度神经网络提取源代码特征(参见第V-C节)。
深度神经网络(DNN)的优势在于,它们能够紧凑地表示比浅层网络显著更广泛的函数集,其中每个函数专门处理输入的某一部分。这一能力使得DNN能够建模输入与输出(即预测)之间的复杂关系。例如,考虑图8,该图可视化了DeepTune [78] 在预测OpenCL内核的最优线程粗化因子时的内部状态(参见第II-D节)。图8(a)展示了输入源代码符号的前80个元素的热力图,其中每个单元格的颜色反映了分配给特定符号的整数值。图8(b)则展示了针对四个GPU平台的第一个DNN层的神经元,使用红-蓝热力图可视化每个激活的强度。如果我们仔细观察热力图,可以发现该层中有多个神经元在不同平台上具有不同的响应。这表明DNN在一定程度上是专门针对目标平台进行优化的。随着信息在网络中的传播(图8中的层©和(d)),各层会逐渐对特定平台进行更为专业化的处理。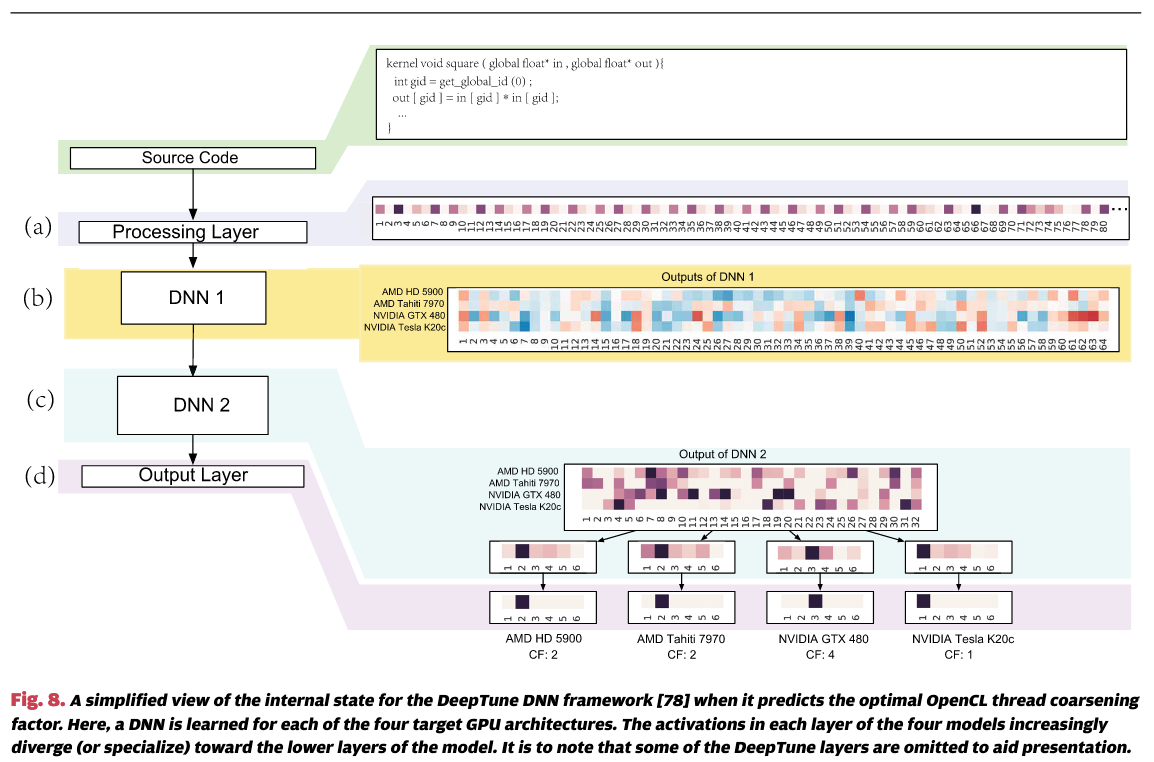
Unsupervised Learning
与监督学习模型通过学习输入特征值与对应输出之间的关联不同,无监督学习模型仅从输入数据(例如,特征值)中提取信息。这种技术通常用于建模数据分布的潜在结构。
聚类是一个经典的无监督学习问题。K均值聚类算法 [90] 将输入数据分成k个簇。例如,在图9中,使用K均值算法将数据点在二维特征空间中分为三个簇。该算法的工作原理是将特征空间中相互接近的数据点分为同一簇。K均值被用于表征程序行为 [60],[91]。具体来说,它通过将程序执行分为不同的阶段组来进行聚类,从而我们可以使用该组中的少数样本来代表该组内的所有程序阶段。K均值还被用于[92]中的研究,以总结受益于相似优化策略的并行程序的代码结构。除了K均值,Martins等人还采用了快速Newman聚类算法 [93],该算法作用于网络结构,能够将可能受益于相似编译优化的函数进行分组 [94]。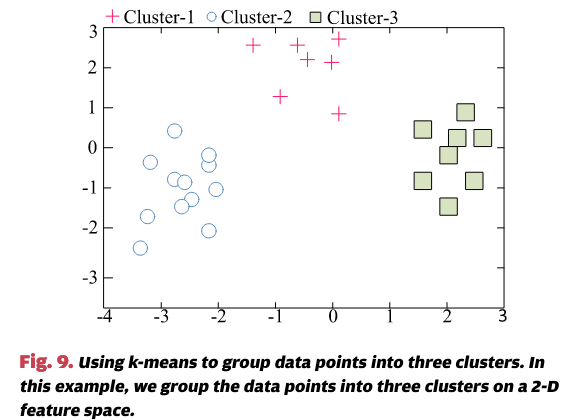
主成分分析(PCA)是一种用于无监督学习的统计方法。在之前的研究中,这种方法被广泛应用于减少特征维度 [17],[25],[95]–[97]。通过这种方式,我们可以使用较少的代表性变量来建模高维特征空间,这些变量的组合能够描述原始特征空间中的大部分变异性。PCA通常用于发现数据集中的共性模式,从而有助于聚类任务。它被用于从基准套件中选择代表性程序 [95],[98]。在第V-D节中,我们将进一步讨论PCA。
自编码器是最近提出的一种人工神经网络架构,用于以非监督方式发现输入数据的高效编码 [99]。这种技术可以与自然语言模型结合使用,首先从程序源代码中提取特征,然后找到源代码特征的紧凑表示 [100]。在回顾特征维度减少技术时,我们将在第V-D节中讨论自编码器。
Online Learning
进化搜索
进化算法(EAs)或进化计算,如遗传算法(GAs)、遗传编程(GP)和基于随机搜索的方法,已被用来从广泛的搜索空间中找到良好的优化解。进化算法通过应用受生物进化启发的原则,寻找目标问题的最优或近似最优解。例如,SPIRAL自动调优框架使用随机进化搜索算法来选择适用于信号处理应用的快速公式(或转换)[101]。Li等人使用遗传算法(GAs)根据未排序数据的大小搜索最优配置,以决定使用哪种排序算法[102]。Petabricks编译器通过使用进化算法为程序员指定的一组算法搜索最佳配置,从而提供了更通用的解决方案[103]。除了代码优化,进化算法还被用于根据不同标准创建帕累托最优程序基准[104]。
举例来说,考虑在迭代编译的上下文中,如何使用进化算法找到程序的最佳编译器标志 [25],[36],[105]。图10展示了进化算法如何用于此目的。算法从多个随机选择的编译器标志设置种群开始。它使用每个个体的编译器标志序列来编译程序,并使用适应度函数来评估编译器标志序列的性能。在我们的例子中,适应度函数可以简单地返回程序运行时间测量的倒数,这样,执行时间较快的编译器设置将具有更高的适应度分数。在下一代中,进化算法通过复制(交叉)和变异等机制生成新的编译器设置种群。这将产生新一代的编译器标志设置,并且每个设置的质量将再次被评估。在类似于自然选择的机制中,每一代中表现不佳的编译器标志会被选中“淘汰”。该过程在没有进一步改进或达到最大代数时终止,算法将返回找到的最佳程序二进制文件作为结果。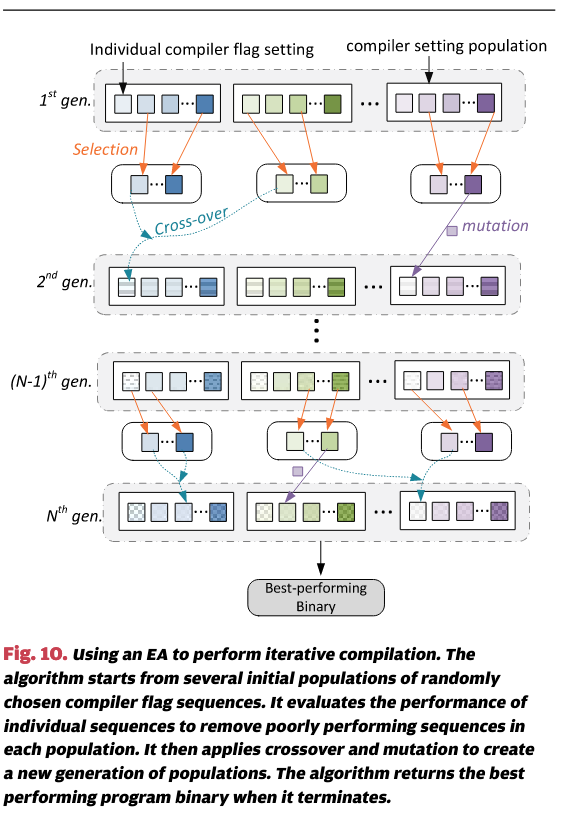
进化算法中的三个关键操作是选择、交叉和变异。优化选项被选中“淘汰”的概率通常与其适应度分数成反比。换句话说,相对较好的选项(例如,提供更快程序运行时间的选项)更有可能在选择后存活,并继续留在种群中。在交叉操作中,通过混合一些现有的优化选项(如编译器标志)来生成一定数量的后代。现有选项被选中进行交叉的概率也与其适应度成正比。这一策略确保了好的优化在代际中得以保留,而表现不佳的优化则逐渐消失。最后,变异操作随机地改变一个保留下来的优化选项,例如,打开/关闭一个选项或替换编译器标志序列中的阈值。变异操作减少了算法陷入局部最优解的机会。
进化算法对于探索一个庞大的优化空间非常有用,在这种情况下,单纯枚举所有可能的解决方案是不可行的。这是因为进化算法通常比一般的搜索启发式方法更快地收敛到优化空间中最有前景的区域。进化算法在寻找快速傅里叶变换(FFT)的最优转换时,已被证明比基于动态规划的搜索更为高效 [101]。与监督学习相比,进化算法的优势在于它们对问题特定知识的需求较少,因此可以应用于广泛的问题。然而,由于进化算法通常依赖于经验性证据(如运行时间)来进行适应度评估,因此搜索时间可能仍然非常昂贵。可以通过使用基于机器学习的成本模型 [43] 来估算配置的潜在收益(例如加速比),从而减少这种开销(参见第III-A节)。另一种方法是通过先使用离线学习的模型来预测设计空间中最有前景的区域(即缩小搜索范围),然后在预测的区域内进行搜索以优化解 [25],[106]。此外,除了预测在哪些搜索空间中集中关注外,还可以通过修剪搜索空间来减少需要搜索的选项数量。例如,Jantz和Kulkarni展示了,如果首先去除那些其应用顺序对生成的代码无关紧要的阶段,阶段排序的搜索空间可以大大缩小 [107]。他们的技术声称能够平均修剪89%的阶段顺序搜索空间。
强化学习:
另一类在线学习算法是强化学习(RL),有时被称为“从交互中学习”。该算法尝试学习如何最大化奖励(或性能)。换句话说,算法需要学习,在给定输入的情况下,采取什么样的正确输出或决策。这与监督学习不同,后者在训练数据中提供了正确的输入/输出对。
图11展示了强化学习的工作机制。学习算法在离散的时间步长中与环境进行交互。在每个时间步,算法评估环境的当前状态,并执行一个动作。该动作导致环境状态的变化(算法可以在下一个时间步中评估该状态),并产生即时奖励。例如,在多任务环境中,状态可能是CPU竞争;当处理器核心空闲时,动作可以是将一个进程放置在哪里,而奖励则可能是整个系统的吞吐量。强化学习的目标是通过学习一个最优策略,将状态映射到动作,从而最大化长期的累积奖励。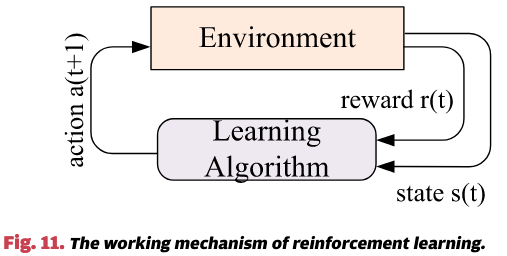
强化学习特别适用于建模具有动态特性的任务,例如动态任务调度,在这种情况下,最优结果是通过一系列动作实现的。强化学习已被应用于先前的研究中,用于调度RAM内存流量[108]、选择运行时软件组件配置[109]以及配置虚拟机[110]。使用强化学习进行程序优化的早期工作由Lagoudakis和Littman [111]进行。他们使用强化学习来确定在两种排序算法——快速排序和插入排序之间切换的临界点。CALOREE结合了机器学习和控制理论,用于在异构多核上调度CPU资源[112]。对于给定的应用程序,CALOREE使用控制理论方法动态调整资源分配,并利用机器学习估算给定资源分配方案的应用延迟和功耗(以提供决策支持)。
在[113]中,提出了一种有趣的基于强化学习的调度方法,旨在调度并行OpenMP程序。该方法预测目标OpenMP程序在与其他竞争工作负载一起运行时的最佳线程数,目的是加速目标程序的运行。该方法首先基于静态代码特征和运行时系统信息离线学习一个奖励函数。奖励函数用于估算运行时调度动作的奖励,即分配一定数量的处理器核心给OpenMP程序时的预期加速比。在下一次调度周期中,该方法通过对应用程序加速比的经验观察,检查奖励函数是否准确,决策是否有效,并在发现模型不准确时更新奖励函数。
总体而言,强化学习是一个直观且全面的自主决策解决方案。但其性能取决于价值函数的有效性,价值函数用于估算即时奖励。一个最优的价值函数应当能够在更长的时间内带来最大的累积奖励。对于许多问题来说,设计有效的价值函数或策略是困难的,因为该函数需要预测一个动作在未来的影响。强化学习的有效性还依赖于环境;如果可能的动作数量较大,强化学习可能需要较长时间才能收敛到一个好的解决方案。强化学习还要求环境是完全可观察的,即环境的所有可能状态可以提前预见。然而,由于不可预测的干扰,例如应用程序输入或应用程序组合的变化,这一假设在动态计算环境中可能不成立。近年来,深度学习技术与强化学习结合使用,以学习价值函数。这种结合的技术能够解决过去被认为不可能解决的一些问题[114]。然而,如何将深度学习与强化学习结合,解决编译和代码优化问题仍然是一个悬而未解的问题。
Discussion
什么模型最好是一个价值64,000美元的问题。答案是:它取决于情况。
更复杂的技术可能提供更高的准确性,但它们需要大量标注的训练数据——这是编译优化中的一个实际问题。与SVM和人工神经网络(ANNs)等更先进的模型相比,线性回归和决策树等技术需要的训练数据较少。当预测问题可以通过特征向量来描述,并且该特征向量与预测结果之间存在线性相关性时,简单模型通常效果较好。像SVM和ANN这类更先进的技术可以在更高维的特征空间中建模线性和非线性问题,但它们通常需要更多的训练数据来学习有效的模型。此外,SVM和ANN的性能还高度依赖于训练模型时使用的超参数。通过对训练数据执行交叉验证,可以选择最佳的超参数值。然而,如何选择超参数以避免过拟合,同时实现良好的预测准确性,仍然是一个悬而未解的挑战。
选择使用哪种建模技术并非易事。这是因为模型的选择依赖于多个因素:预测问题(例如回归或分类)、要使用的特征集、可用的训练示例、训练和预测的开销等。在之前的研究中,建模技术的选择主要依赖于开发者的经验和实证结果。许多基于机器学习的代码优化研究并没有充分论证模型选择的理由,尽管有些研究会比较不同技术的性能。OpenTuner框架通过使用多种技术进行程序调优,解决了这一问题[115]。OpenTuner同时运行多种搜索技术。表现良好的技术会获得更多候选调优选项,而表现差的算法则会被分配更少的选择或完全禁用。通过这种方式,OpenTuner可以在搜索过程中发现哪种算法最适合给定的问题。
一种较少被研究的技术是高斯过程[116]。在最近深度神经网络(DNN)广泛流行之前,这种方法在许多机器学习领域中曾非常受欢迎[117]。当训练数据稀缺且收集成本高时,高斯过程尤其强大。它们还会自动给出任何决策的置信区间。这使得编译器开发者可以根据应用场景,在风险与回报之间进行权衡。
Feature Engineering
基于机器学习的代码优化依赖于一组高质量的特征,这些特征能够捕捉目标程序的关键特性。由于潜在特征的数量是无限的,找到合适的特征集是一个非平凡的任务。在本节中,我们回顾了先前研究中如何选择特征,这一过程被称为特征工程。表4和表5分别总结了本节讨论的程序特征和特征工程技术的范围。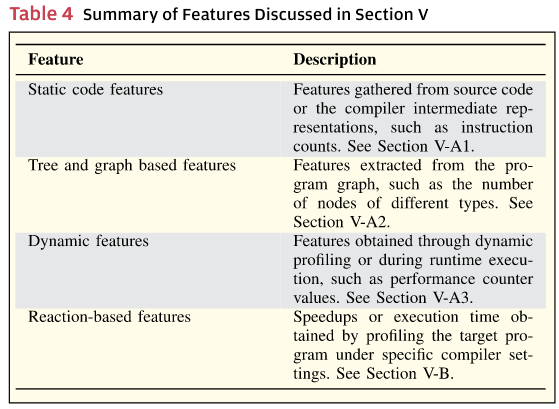

Feature Representation
在基于编译器的机器学习中,使用了各种形式的程序特征。这些特征包括静态代码结构 [122] 以及运行时信息,如系统负载 [118],[123] 和性能计数器 [53]。
静态代码特征:
静态程序特征,如指令的数量和类型,常用于描述程序。这些特征通常从编译器的中间表示中提取 [29],[46],[52],[80],以避免使用从死代码中提取的信息。表6列出了先前研究中使用的一些静态代码特征。原始代码特征通常会结合在一起形成一个综合特征。例如,可以将加载指令的数量除以总指令数,从而得到内存负载比率。使用静态代码特征的一个优势是,这些特征可以从编译器的中间表示中轻松获取。
基于树和图的特征:
Singer和Veloso将FFT表示为分裂树 [124]。他们从树中提取了一组特征,通过计算各种类型节点的数量并量化树的形状。这些基于树的特征随后用于构建一个基于神经网络的成本函数,用来预测哪种FFT公式运行得更快。该成本函数用于寻找表现最佳的变换。
Park等人提出了一种独特的基于图的特征表示方法 [125]。他们使用支持向量机(SVM),其核函数基于图相似度度量。他们的方法要求在基本块级别手工编码特征,但之后,图相似度可以替代全局特征,针对每个训练程序进行相似度计算。Mailike表明,从程序的数据流图中提取的空间信息,即指令在程序中的分布,可能是基于机器学习的编译器优化的有用特征 [126]。Nobre等人也利用图结构进行代码生成 [26]。他们的方法解决阶段排序问题。编译优化阶段的顺序表示为图,每个节点是一个优化阶段,节点之间的连接权重使得具有较高聚合权重的子序列更有可能导致更快的运行时间。该图通过迭代编译自动构建和更新(目标程序使用不同的编译阶段和顺序进行编译)。设计空间探索算法被用来驱动迭代编译过程。
动态特征:
尽管静态代码特征有用且可以在编译时提取(因此特征提取没有运行时开销),它们也存在缺点。例如,静态代码特征可能包含一些很少执行的代码段的信息,这些信息可能会干扰机器学习模型;某些程序信息(如循环边界)依赖于程序输入,仅在执行时获得;而且静态代码特征往往无法精确捕捉程序在运行时环境中的行为(如资源竞争和输入/输出行为),因为这些行为高度依赖于计算环境,如可用处理器数量和并发工作负载。
如图12所示,动态特征可以从运行时环境的多个层次中提取。在应用层,我们可以获取诸如循环迭代次数、无法在编译时确定的动态控制流、频繁执行的代码区域等信息。在操作系统级别,我们可以观察应用程序的内存和I/O行为,以及CPU负载和线程竞争等信息。在硬件级别,我们可以使用性能计数器跟踪诸如执行了多少指令、指令类型、缓存加载/存储的次数以及分支未命中的次数等信息。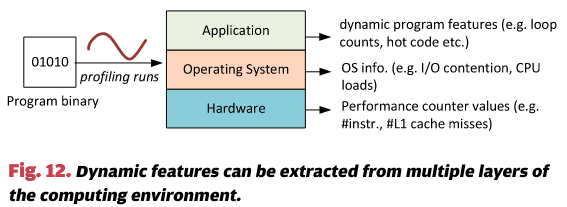
因此,硬件性能计数器值,如执行指令计数和缓存未命中率,被用来理解应用程序的动态行为 [53],[127],[128]。这些计数器能够捕获低级程序信息,如数据访问模式、分支和计算指令。性能计数器的一个优势是,它们捕获目标程序在特定硬件上的行为,并避免了静态代码特征可能带来的无关信息。除了硬件性能计数器,操作系统级别的指标,如系统负载和I/O竞争,也被用来建模应用程序的行为 [39],[123]。这些信息可以在不修改代码的情况下外部观察,并可以在离线分析或程序执行时获得。
尽管收集动态信息非常有效,但它可能会带来过高的开销,而且收集到的信息可能由于竞争工作负载和操作系统调度 [129],甚至执行环境的微妙设置 [130],而带有噪声。性能计数器和动态特征的另一个缺点是,它们只能捕捉到应用程序的过去行为。因此,如果应用程序由于程序阶段或输入的变化在未来表现出显著不同的行为,那么基于这些不可靠的观察得出的预测可能会产生偏差。因此,在先前的研究中,通常将动态特征和静态特征结合使用,以构建一个更加稳健的模型。
Reaction-Based Features
Cavazos等人提出了一种基于反应的预测模型,用于软件–硬件协同设计 [131]。他们的方法通过使用若干精心选择的编译器选项对目标程序进行分析,观察在这些选项下程序运行时如何随给定微架构设置变化。然后,他们利用程序的“反应”来预测最佳的应用加速效果。图13展示了基于反应的模型与标准程序特征模型之间的区别。类似的基于反应的方法也被应用于[132],用于在给定的微架构配置下预测应用程序的加速和能效,该程序通过线程级推测(TLS)进行并行化。需要注意的是,尽管基于反应的方法不使用静态代码特征,但开发人员必须从大量候选选项中精心选择一些配置进行分析,因为选项选择不当可能会显著影响模型的质量。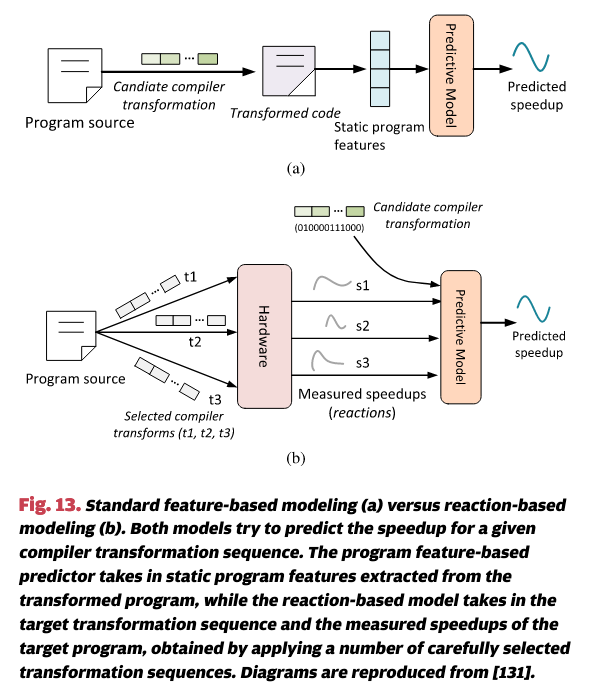
Automatic Feature Generation
由于提取良好的特征是一项耗时的任务,因此一些方法被提出以自动生成来自编译器中间表示(IR)的特征 [70],[133]。其中,[70]的工作使用遗传编程(GP)来搜索特征,但需要编写一个庞大的语法,约160 kB。尽管其中大部分可以通过模板生成,但选择正确的功能范围和搜索空间的偏差并非易事,且需要专家的判断。[133]的工作通过逻辑编程表达特征空间,这些逻辑编程关系表示来自IR的信息。它通过贪婪地搜索表达式来代表良好的特征。然而,他们的方法依赖于专家选择的关系、组合器和约束条件来实现。这两种方法都将预测模型的实现与编译器IR紧密绑定,这意味着IR的任何变化都会要求对模型进行修改。此外,这些方法在特征搜索上花费的时间可能是相当可观的。
首个采用神经网络从程序源代码中提取特征进行编译器优化的工作是Cummins等人进行的 [78]。他们的系统——DeepTune,自动从原始源代码中抽象和选择适当的特征。与以往的工作不同,传统的预测模型需要输入一组人工设计的特征,而DeepTune直接使用程序代码作为训练数据。程序通过一系列基于神经网络的语言模型进行处理,学习代码如何与期望的优化选项相关(参见图8)。他们的研究还表明,神经网络顶部层次抽象出的原始代码特性大多与优化问题无关。虽然这一方法具有前景,但值得提到的是,像程序输入大小和性能计数器值这样的动态信息通常对于描述目标程序的行为至关重要。因此,当静态代码特征不足以解决优化问题时,DeepTune并没有完全消除人工参与特征工程的需求。
Feature Selection and Dimension Reduction
机器学习通过特征来捕捉训练示例的基本特征。有时,我们会面临特征过多的问题。随着特征数量的增加,构建准确模型所需的训练示例数量也会增加 [134]。因此,我们需要限制特征空间的维度。在编译器研究中,通常会通过特征选择 [52] 或将特征投影到低维空间 [17] 来修剪初始的大规模高维候选特征空间。本节中,我们回顾了若干特征选择和降维方法。
1. 特征选择:
特征选择需要理解某个特征如何影响预测准确性。实现这一目标的最简单方法之一是应用皮尔逊相关系数。这一度量衡量两个变量之间的线性相关性,并在许多研究中使用 [55],[92],[122],[135] 来过滤冗余特征,方法是移除那些与已经选择的特征高度相关的特征。它还被用来量化选择特征在回归中的关系。使用皮尔逊相关系数作为特征排序机制的一个明显缺点是它仅对线性关系敏感。
另一种相关性估计方法是互信息 [131],[136],它量化了通过一个变量(或特征)能够获得多少关于另一个变量(特征)的信息。与相关系数类似,互信息也可以用来移除冗余特征。例如,如果特征x的信息大部分可以通过另一个现有特征y获得,那么可以从特征集中移除特征x,而不会丢失太多信息。
皮尔逊相关系数和互信息都独立地评估每个特征对预测的影响。另一种方法是利用回归分析来进行特征排序。回归分析的基本原理是,如果预测是基于特征的回归模型的结果,那么最重要的特征应该在模型中具有最高的权重(或系数),而与输出变量无关的特征应该具有接近零的权重。例如,最小绝对收缩和选择算子(LASSO)回归分析在 [137] 中被用来移除不太有用的特征,以构建一个基于编译器的模型来预测性能。LASSO也被用于特征选择,以调整TRIPS处理器的编译器启发式方法 [138]。
通常,特征选择仍然是机器学习中的一个开放问题,研究人员常常采用“试错”方法来测试一系列方法和特征候选。正因如此,像FEAST [139] 和 HERCULES [140]这样的自动特征选择框架显得尤为吸引人。前者框架采用一系列现有的特征选择方法来选择有用的候选特征,而后者则从一组预定义的循环模式中搜索最重要的静态代码特征。
2. 特征维度降低:
虽然特征选择允许我们选择最重要的特征,但得到的特征集可能仍然过于庞大,难以训练出一个良好的模型,尤其是当训练示例较少时。通过降低维度,学习算法通常能够在有限的训练数据集上更高效地运行。维度降低对于一些机器学习算法,如KNN,尤为重要,因为它有助于避免维度灾难的影响 [141]。
主成分分析(PCA)是一种成熟的特征降维技术 [142]。它使用正交线性变换来降低一组变量(在这里指特征)的维度。
图14演示了如何使用PCA来降低维度。此示例中的输入是由M1、M2和M3定义的3D空间,如图14(a)所示。首先计算三个成分P C1、P C2和P C3,它们分别解释数据的方差。在这里,P C1和P C2贡献了大部分数据的方差,而P C3则解释了最少的方差。只使用P C1和P C2,我们就可以将原始的3D空间转换成一个新的2D坐标系统 [如图14(b)所示],同时保留了原始数据的主要方差。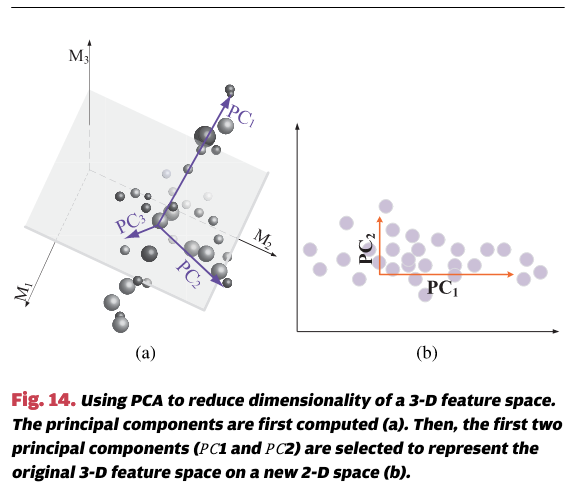
PCA已被许多编译器研究用于特征降维 [17],[25],[55],[92],[95]–[97],[143]。它也常用于以前的工作中,用来可视化机器学习模型的工作机制,例如,通过将高维空间中的特征投影到二维空间中,展示基准测试如何在特征空间中分组 [123]。
我们要强调的是,PCA并不是选择某些特征并丢弃其他特征,而是通过线性组合原始特征来构造新的特征,这些新特征能够概括原始特征的集合。当原始特征之间存在冗余时,PCA是非常有用的,即一些特征与其他特征相关。类似的特征降维方法还包括因子分析和线性判别分析(LDA),它们都试图通过线性组合多个原始特征来减少特征的数量。然而,PCA似乎是编译器研究中最常用的特征降维方法,可能是因为它的简单性。
另一种减少使用特征数量的方法是通过自动编码器 [144]。它是一种神经网络,通过降维来寻找数据集的表示(编码)。自动编码器通过从输入数据中学习编码器和解码器来工作。编码器试图将原始输入压缩成低维表示,而解码器则根据编码器生成的低维表示尝试重建原始输入。因此,自动编码器被广泛用于去除数据噪声以及减少数据维度 [145]。
自动编码器已被应用于各种自然语言处理任务 [99],通常与深度神经网络(DNN)一起使用。最近,它被用于建模程序源代码,以获得能够表征输入程序源的紧凑特征集 [78],[146]–[149]。
Scope
机器学习已经被应用于解决广泛的问题,从早期成功的用于选择顺序程序编译器选项的研究,到最近在异构多核系统上调度和优化并行程序的工作。本节将回顾先前研究中所涉及的各类问题。
Optimizing Sequential Programs
早期的编译器中机器学习应用研究主要探讨了是否以及如何将编译优化应用于顺序程序。一些先前的研究构建了监督学习分类器,以预测最佳的循环展开因子[52],[70],或判断一个函数是否应当内联[29],[35]。这些研究针对一组固定的编译器选项,通过将优化问题表示为多类分类问题,其中每个编译器选项对应一个类别。例如,Leather 等人[70]考虑了一个介于0到15之间的循环展开因子(共16种配置),将每个候选的展开因子视为一个类别;他们通过尝试所有16种配置来编译和分析每个训练程序,从中找出每个程序的最佳循环展开因子,并从训练数据中学习一个决策树模型。
还有一些编译器问题涉及的选项数量庞大。例如,[55]的研究考虑了GCC的54种代码转换选项。虽然这些选项仅是GCC提供的数百种转换中的一个子集,但由此产生的组合编译器配置导致了大约 的配置空间。尽管可以构建分类器来直接预测从如此庞大的空间中选择的最佳设置,但要学习一个有效的模型,仍然需要大量的训练程序,以便在空间中进行足够的采样。这是困难的,因为1)可用的基准测试程序只有几十个;2)编译器开发者需要自己生成训练数据。
像通用搜索这样的进化算法(EAs)常常被用于探索大规模的设计空间(参见第四节C1小节)。先前的研究已经使用进化算法解决了如阶段排序问题(即应按何种顺序应用一组编译器转换)[150]–[152]、在迭代编译过程中确定编译器标志[153]–[156]、选择循环转换[157]、调优算法选择[11],[103]等问题。
Optimizing Parallel Programs
如何有效优化并行程序在过去十年中受到了广泛关注,主要是因为硬件行业采用了多核设计以避免功耗瓶颈[158]。虽然多核和多处理器架构提供了高性能和能效计算的潜力,但只有当应用程序适当并行并能够与底层异构平台匹配时,才能释放其潜在性能。如果没有这一点,多核处理器上的众多核心及其专用处理单元将处于空闲状态或未充分利用。为此,研究人员已将机器学习的应用扩展到并行程序的优化中。
并行程序优化的一个研究方向是并行性映射。即,给定一个已经并行化的程序,如何将应用程序的并行性映射到底层硬件,以使程序运行得尽可能快或尽可能节能。Zhang 等人开发了一种基于决策树的方法,用于预测 OpenMP 并行区域的调度策略[159]。在[46]中,使用了两种机器学习技术来预测 OpenMP 并行循环的最佳线程数以及调度策略。具体来说,它使用基于回归的 ANN 模型来预测在给定线程数下并行循环的加速比(以搜索最佳线程数),并使用 SVM 分类器来预测调度策略。还有一些工作使用机器学习来确定事务内存[160]和硬件资源分配[161]的最佳并行度,或从多个选项中选择要使用的代码版本[162]。Castro 等人开发了一个决策树分类器,用于预测软件事务内存中的线程映射策略[163]。Jung 等人构建了一个基于 ANN 的预测器,用于在特定微架构上选择有效的数据结构[164]。
[92] 和 [165] 中提出的工作为应用机器学习映射具有无限并行图结构的复杂并行程序提供了一种独特的方法。该研究考虑了如何找到流式程序的最佳图结构。其思路是,不是尝试预测一个无限图的转换序列,在这种情况下合法性和一致性是真正的问题,而是应该从对偶特征空间的角度来考虑问题。研究表明,可以预测最佳目标特征(即理想转换程序应具有的特性),然后可以在原始特征空间中评估候选转换图的价值(而无需编译和分析生成的图)。
Petabricks 项目[103],[166],[167]采取了进化方法进行程序调优。Petabricks 编译器采用遗传搜索算法来调优算法选择。由于搜索的开销较大,大部分自动调优是在静态编译时进行的。他们的工作表明,可以利用多核系统中的空闲处理器执行在线调优[168],即一半核心用于已知的安全程序配置,另一半核心用于实验性程序配置。通过这种方式,当较快配置的结果返回时,较慢版本将被终止。
结合编译时知识和运行时信息以实现更好的优化的思路已被 ADAPT 编译器[169]所采用。使用 ADAPT 编译器时,用户描述可用的优化内容,并提供应用这些优化的启发式方法。编译器然后读取这些描述并生成应用程序特定的运行时系统来应用这些启发式方法。运行时代码调优也被 Active Harmony[170]所采用,该系统利用高性能计算(HPC)系统中的计算资源在不同节点上评估不同的代码变体,以找到最佳性能版本。
在异构多核系统上优化程序的研究也有大量的相关工作。异构多核优化的一个问题是确定何时以及如何使用异构处理器。研究人员已使用机器学习构建分类器来确定使用哪个处理器[68],以及处理器应在哪个时钟频率下运行[80],[171]。其他研究则使用回归技术构建曲线拟合模型,以寻找处理器之间工作划分的最佳点[38],或在能效与性能之间的权衡点[172]。
另一个研究方向是将编译器分析与机器学习结合,用于优化存在竞争工作负载的程序。这个研究问题很重要,因为程序很少独立运行,它们必须与其他并行运行的工作负载共享计算资源。在[173]和[174]中,构建了一个基于静态代码特征和运行时信息的人工神经网络(ANN)模型,用于预测在与外部工作负载并行运行时,目标程序使用的线程数。随后,在[118]中使用了一种基于集成学习的方法,相比[173],其性能得到了显著提升。在[118]中,首先离线训练多个模型;然后,在运行时选择一个模型,考虑到并行工作的工作负载和可用硬件资源。核心思想是,不使用一个单一的庞大模型,而是使用多个模型,每个模型专门用于建模某个应用程序子集或特定运行时场景。通过这种方法,当模型的预测有效时,就使用该模型。
最近的一些研究开发了基于静态代码特征和动态运行时信息的机器学习模型,用于调度 OpenCL 程序,尤其是在 GPU 竞争的情况下。[175]中提出的工作使用 SVM 分类来预测在多个程序争抢在单一 GPU 上运行时,CPU 和 GPU 之间的工作划分比。[39]中的研究旨在提高系统的整体吞吐量,尤其是在多个 OpenCL 程序争夺在 GPU 上运行时。他们开发了一个人工神经网络(ANN)模型,用于预测在 GPU 上运行 OpenCL 内核的潜在加速比。然后,利用加速比预测作为代理来确定哪些等待的 OpenCL 任务能够在 GPU 上运行,并决定它们的执行顺序。
[176] 和 [177] 中提出的方法针对数据中心环境中的任务共置问题。它们使用基于编译器的代码转换来减少多个并行任务之间的资源争用。通过性能计数器值计算代码区域的争用得分,采用线性回归模型来执行此计算。随后,应用一组基于编译器的代码转换,减少高争用代码的资源需求。
Other Research Problems
许多研究表明,机器学习在性能和成本建模[47],[178]–[180]以及任务和资源调度[161],[181]–[183]方面是一种强大的技术。我们预见到,许多这些技术可以被用来提供证据,支持通过例如即时编译(just-in-time compilation)进行的运行时程序优化。
尽管机器学习并不直接针对代码优化,基于编译器的代码分析和机器学习技术已被结合使用来解决各种软件工程任务。这些任务包括检测代码相似性[184],[185]、自动生成注释[186]、挖掘API使用模式[187],[188]、预测程序属性[189]、恶意软件检测中的代码去混淆[190]等。值得注意的是,许多近期的研究表明,从大型代码库(如GitHub)中提取的过去开发知识对于学习有效的模型具有重要价值。Cummins等人最近进行了两项研究,分别通过挖掘GitHub来合成OpenCL基准[148]和从源代码中提取代码特征[78]。这两项研究均展示了大型代码库和深度学习技术在为编译器优化学习预测模型方面的实用性。我们预见到,大型开源代码库中的丰富信息可以为训练机器学习模型以解决编译器优化问题提供一个强大的知识库,而深度学习可以作为一种有效工具,从海量的程序源代码中提取这些知识。
Discussion
基于机器学习的方法的一个真正优势是,==它强制采用基于经验的方法来构建编译器。新的模型必须依赖于经验数据,并且这些数据可以通过独立的实验进行验证。==这种实验、假设、测试的循环在物理科学中是广为人知的,但在编译器构建中则是相对较新的做法。
由于基于机器学习的技术需要对优化空间进行采样以获取训练数据,我们通常能够知道训练集中每个程序的最佳优化。如果我们将这个基准排除在训练之外,那么我们就可以获得该程序的性能上限或“预言机”。这可以立即告诉我们现有技术的优劣。如果它们达到了最优性能的50%或95%,我们就可以立即判断这个问题是否值得继续探索。
此外,==我们可以构造一些简单的技术,例如随机优化,并观察其性能。==如果这种方法运行多次,它将会有一个优化加速比的平均期望值。然后,我们可以要求任何新的启发式方法必须超过这个值,尽管根据我们的经验,有些最先进的工作实际上表现得还不如随机优化。
Not a Panacea
本文总体上对机器学习在编译器中的应用持乐观态度。然而,要将其变为实际可行的技术,还有许多障碍需要克服,这也引出了有关优化的新问题。
训练成本是许多人关注的一个问题。实际上,训练成本远低于编译器开发者的成本,并且可以采用主动学习等技术来减少训练数据生成的开销[191]–[194]。尽管可以说,生成许多不同编译的程序并执行和计时这些程序完全是自动化的,但找到合适的数据需要仔细考虑。如果所探索的优化对程序的性能几乎没有正面影响,那么就没有值得学习的内容。
最紧迫的问题仍然是收集足够的高质量训练数据。尽管有许多公开的基准网站,但与一个典型编译器在其生命周期内可能遇到的程序数量相比,可用的程序数量相对较少。特别是在某些专业领域,可能没有任何公开的基准。自动基准生成的研究工作将在这方面提供帮助,但现有的方法并不能保证生成的基准能够有效地代表设计空间。因此,程序空间结构的更大问题依然存在。
一个真正的根本问题是,如果我们仅仅基于经验数据来构建优化模型,那么我们必须保证这些数据是正确且具有代表性的;我们必须学习信号,而不是噪声。机器学习方法的同行评审是非常困难的。与手工编写的启发式方法不同,黑箱模型使得模型的质量难以受到质疑。从某种意义上说,评审人员现在必须审查实验是否公正地进行。这意味着所有的训练和测试数据必须公开,供人审查。这在其他经验科学中是常见做法。人工制品评估委员会便是这种做法的一个例子[195],[196]。
尽管自动学习如何优化应用程序并适应变化是一个巨大的进步,但机器学习只能从编译器开发者提供的数据中学习。机器学习无法发明新的程序转换方法,也无法推导出判断转换是否合法的分析方法;这一切都超出了它的范畴。
Will This Put Compiler Writers Out of a Job?
实际上,基于机器学习的编译将悖论性地推动编译优化的复兴。编译器已经变得非常复杂,以至于添加一个新的优化或编译阶段可能导致性能回退。这反过来促使了保守的心态,新的转换如果可能会影响现有系统的稳定性,往往不会被考虑。核心问题在于,系统复杂到无法确切知道何时使用某种优化。机器学习可以通过自动确定何时优化是有利的,从而消除这种不确定性。这使得编译器开发者可以自由地开发更为复杂的技术。他们不再需要担心这些新技术如何与其他优化相互干扰——机器学习会处理这一问题。现在,我们可以开发那些通常只适用于特定领域的优化,而不必担心如何将其整合进通用系统中。它使得不同的社区能够开发出创新的优化,并自然地将其整合。因此,机器学习不仅没有限制新想法的出现,反而为新思路开辟了新的视野。
Open Research Directions
机器学习已经证明其在自动化编译器盈利性分析中的实用性。它将继续用于更复杂的优化问题,并可能在未来十年内成为选择编译器优化的默认方法。
当前的开放研究方向不仅仅局限于预测应该应用哪些最佳优化。==一个核心问题是程序空间的形态。我们知道,具有线性数组访问的完美循环嵌套程序与分布式图处理程序需要不同的处理方式。==如果我们能拥有一个可以衡量程序之间距离的“地图”,那么我们就能够看到哪些区域适合通过编译器特征化来优化,而哪些区域是稀缺的、目前被忽视的。如果我们能够对硬件做同样的事情,那么我们可能会更好地设计出适合新兴应用的硬件。
机器学习能否同样应用于编译器分析?例如,是否能够通过机器学习来学习数据流分析或点到分析?由于深度学习具有自动构建特征的能力,我们是否能够找到一组在所有优化和分析中通用的特征?我们能否学习出理想的编译器中间表示?还有许多有趣的研究问题尚未被探索。
Conclusions
本文介绍了基于机器学习的编译,并描述了其在确定基于证据的编译器优化方法中的强大作用。这是编译器自动化50年历程中的最新阶段。基于机器学习的编译现已成为主流的编译器研究领域,并且在过去十年左右,已经产生了大量的学术兴趣和研究论文。尽管无法提供所有研究的全面目录,我们尽力提供了一份全面且易于理解的主要研究领域及未来发展方向的综述。机器学习并非万能药。它只能学习我们提供的数据。与某些人担心的情况相反,它并没有削弱编译器作者的作用,而是为更大的创造力和新的研究领域开辟了可能性。
References
J. Chipps, M. Koschmann, S. Orgel, A. Perlis, and J. Smith, “A mathematical language compiler,” in Proc. 11th ACM Nat. Meeting, 1956, pp. 114–117.
P. B. Sheridan, “The arithmetic translator- compiler of the IBM FORTRAN automatic coding system,” Commun. ACM, vol. 2, no. 2, pp. 9–21, 1959.
M. D. McIlroy, “Macro instruction extensions of compiler languages,” Commun. ACM, vol. 3, no. 4, pp. 214–220, 1960.
A. Gauci, K. Z. Adami, and J. Abela. (2010). “Machine learning for galaxy morphology classification.” [Online]. Available: https:// arxiv.org/abs/1005.0390
H. Schoen, D. Gayo-Avello, P. T. Metaxas, E. Mustafaraj, M. Strohmaier, and P. Gloor, “The power of prediction with social media,” Internet Res., vol. 23, no. 5, pp. 528–543, 2013.
Slashdot. (2009). IBM Releases Open Source Machine Learning Compiler. [Online]. Available: https://tech.slashdot.org/ story/09/07/03/0143233/ibm-releases-open- source-machine-learning-compiler
H. Massalin, “Superoptimizer: A look at the smallest program,” ACM SIGPLAN Notices, vol. 22, no. 10, pp. 122–126, 1987.
J. Ivory, “I. On the method of the least squares,” Philos. Mag. J., Comprehending Various Branches Sci., Liberal Fine Arts, Agriculture, Manuf. Commerce, vol. 65, no. 321, pp. 3–10, 1825.
R. J. Adcock, “A problem in least squares,” Analyst, vol. 5, no. 2, pp. 53–54, 1878.
K. Datta et al., “Stencil computation optimization and auto-tuning on state-of- the-art multicore architectures,” in Proc. ACM/IEEE Conf. Supercomput., Nov. 2008, pp. 1–12.
J. Ansel, Y. L. Wong, C. Chan, M. Olszewski, A. Edelman, and S. Amarasinghe, “Language and compiler support for auto-tuning variable-accuracy algorithms,” in Proc. Int. Symp. Code Generat. Optim. (CGO), Apr. 2011, pp. 85–96.
J. Kurzak, H. Anzt, M. Gates, and J. Dongarra, “Implementation and tuning of batched Cholesky factorization and solve for NVIDIA GPUs,” IEEE Trans. Parallel Distrib. Syst., vol. 27, no. 7, pp. 2036–2048, Jul. 2016.
Y. M. Tsai, P. Luszczek, J. Kurzak, and J. Dongarra, “Performance-portable autotuning of OpenCL kernels for convolutional layers of deep neural networks,” in Proc. Workshop Mach. Learn. HPC Environ. (MLHPC), 2016, pp. 9–18.
M. E. Lesk and E. Schmidt, “Lex—A lexical analyzer generator,” Tech. Rep., 1975.
S. C. Johnson, Yacc: Yet Another Compiler- Compiler, vol. 32. Murray Hill, NJ, USA: Bell Laboratories, 1975.
A. Monsifrot, F. Bodin, and R. Quiniou, “A machine learning approach to automatic production of compiler heuristics,” in Proc. Int. Conf. Artif. Intell. Methodol. Syst. Appl., 2002, pp. 41–50.
A. Magni, C. Dubach, and M. O’Boyle, “Automatic optimization of thread- coarsening for graphics processors,” in Proc. 23rd Int. Conf. Parallel Archit. Compilation (PACT), 2014, pp. 455–466.
S. Unkule, C. Shaltz, and A. Qasem, “Automatic restructuring of GPU kernels for exploiting inter-thread data locality,” in Proc. 21st Int. Conf. Compil. Construction (CC), 2012, pp. 21–40.
V. Volkov and J. W. Demmel, “Benchmarking GPUs to tune dense linear algebra,” in Proc. ACM/IEEE Conf. Supercomput. (SC), Nov. 2008, pp. 1–11.
Y. Yang, P. Xiang, J. Kong, M. Mantor, and H. Zhou, “A unified optimizing compiler framework for different gpgpu architectures,” ACM Trans. Archit. Code Optim., vol. 9, no. 2, p. 9, 2012.
C. Lattner and V. Adve, “LLVM: A compilation framework for lifelong program analysis & transformation,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2004, pp. 75–86.
F. Bodin, T. Kisuki, P. Knijnenburg, M. O’Boyle, and E. Rohou, “Iterative compilation in a non-linear optimization space,” in Proc. Workshop Profile Feedback- Directed Compilation, 1998.
P. M. Knijnenburg, T. Kisuki, and M. F. O’Boyle, “Combined selection of tile sizes and unroll factors using iterative compilation,” J. Supercomput., vol. 24, no. 1, pp. 43–67, 2003.
M. Frigo and S. G. Johnson, “The design and implementation of FFTW3,” Proc. IEEE, vol. 93, no. 2, pp. 216–231, Feb. 2005.
F. Agakov et al., “Using machine learning to focus iterative optimization,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2006, pp. 295–305.
R. Nobre, L. G. A. Martins, and J. M. P. Cardoso, “A graph-based iterative compiler pass selection and phase ordering approach,” in Proc. 17th ACM SIGPLAN/ SIGBED Conf. Lang. Compil. Tools Theory Embedded Syst. (LCTES), 2016, pp. 21–30.
R. Leupers and P. Marwedel, “Function inlining under code size constraints for embedded processors,” in Dig. Tech. Papers IEEE/ACM Int. Conf. Comput.-Aided Design, Nov. 1999, pp. 253–256.
K. D. Cooper, T. J. Harvey, and T. Waterman, “An adaptive strategy for inline substitution,” in Proc. Joint Eur. Conf. Theory Pract. Softw. 17th Int. Conf. Compil. Construction (CC/ ETAPS), 2008, pp. 69–84.
D. Simon, J. Cavazos, C. Wimmer, and S. Kulkarni, “Automatic construction of inlining heuristics using machine learning,” in Proc. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), 2013, pp. 1–12.
P. Zhao and J. N. Amaral, “To inline or not to inline? Enhanced inlining decisions,” Lang. Compil. Parallel Comput., pp. 405–419, 2004.
T. A. Wagner, V. Maverick, S. L. Graham, and M. A. Harrison, “Accurate static estimators for program optimization,” in Proc. ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 1994, pp. 85–96.
V. Tiwari, S. Malik, and A. Wolfe, “Power analysis of embedded software: A first step towards software power minimization,” in Proc. IEEE/ACM Int. Conf. Comput.-Aided Design, Nov. 1994, pp. 384–390.
K. D. Cooper, P. J. Schielke, and D. Subramanian, “Optimizing for reduced code space using genetic algorithms,” in Proc. ACM SIGPLAN Workshop Lang. Compil. Tools Embedded Syst. (LCTES), 1999, pp. 1–9.
M. Stephenson, S. Amarasinghe, M. Martin, and U.-M. O‘Reilly, “Meta optimization: Improving compiler heuristics with machine learning,” in Proc. ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2003, pp. 77–90.
J. Cavazos and M. F. P. O’Boyle, “Automatic tuning of inlining heuristics,” in Proc. ACM/ IEEE Conf. Supercomput. (SC), Nov. 2005, p. 14.
K. Hoste and L. Eeckhout, “Cole: Compiler optimization level exploration,” in Proc. 6th Annu. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), 2008, pp. 165–174.
M. Kim, T. Hiroyasu, M. Miki, and S. Watanabe, “SPEA2+: Improving the performance of the Strength Pareto Evolutionary Algorithm 2,” in Proc. Int. Conf. Parallel Problem Solving from Nature, 2004, pp. 742–751.
C.-K. Luk, S. Hong, and H. Kim, “Qilin: Exploiting parallelism on heterogeneous multiprocessors with adaptive mapping,” in Proc. 42nd Annu. IEEE/ACM Int. Symp. Microarchit. (MICRO), Dec. 2009, pp. 45–55.
Y. Wen, Z. Wang, and M. F. P. O’Boyle, “Smart multi-task scheduling for OpenCL programs on CPU/GPU heterogeneous platforms,” in Proc. 21st Ann. IEEE Int. Conf. High Perform. Comput. (HiPC), Dec. 2014, pp. 1–10.
E. A. Brewer, “High-level optimization via automated statistical modeling,” in Proc. 5th ACM SIGPLAN Symp. Principles Pract. Parallel Program. (PPOPP), 1995, pp. 80–91.
K. Vaswani, M. J. Thazhuthaveetil, Y. N. Srikant, and P. J. Joseph, “Microarchitecture sensitive empirical models for compiler optimizations,” in Proc. Int. Symp. Code Generat. Optim. (CGO), Mar. 2007, pp. 131–143.
B. C. Lee and D. M. Brooks, “Accurate and efficient regression modeling for microarchitectural performance and power prediction,” in Proc. 12th Int. Conf. Archit. Support Program. Lang. Oper. Syst. (ASPLOS), 2006, pp. 185–194.
E. Park, L.-N. Pouche, J. Cavazos, A. Cohen, and P. Sadayappan, “Predictive modeling in a polyhedral optimization space,” in Proc. 9th Annu. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), Apr. 2011, pp. 119–129.
M. Curtis-Maury, A. Shah, F. Blagojevic, D. S. Nikolopoulos, B. R. de Supinski, and M. Schulz, “Prediction models for multi- dimensional power-performance optimization on many cores,” in Proc. 17th Int. Conf. Parallel Archit. Compilation Techn. (PACT), 2008, pp. 250–259.
K. Singhet et al., “Comparing scalability prediction strategies on an SMP of CMPs,” in Proc. Eur. Conf. Paralell Process., 2010, pp. 143–155.
Z. Wang and M. F. O’Boyle, “Mapping parallelism to multi-cores: A machine learning based approach,” in Proc. 14th ACM SIGPLAN Symp. Principles Pract. Parallel Program. (PPoPP), 2009, pp. 75–84.
Y. Kang et al., “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,” in Proc. 22nd Int. Conf. Archit. Support Program. Lang. Oper. Syst. (ASPLOS), 2017, pp. 615–629.
L. Benini, A. Bogliolo, M. Favalli, and G. De Micheli, “Regression models for behavioral power estimation,” Integr. Comput.-Aided Eng., vol. 5, no. 2, pp. 95–106, 1998.
S. K. Rethinagiri, R. B. Atitallah, and J.-L. Dekeyser, “A system level power consumption estimation for MPSoC,” in Proc. Int. Symp. Syst. Chip (SoC), 2011, pp. 56–61.
S. Schürmans, G. Onnebrink, R. Leupers, G. Leupers, and X. Chen, “Frequency-aware ESL power estimation for ARM cortex-A9 using a black box processor model,” ACM Trans. Embedded Comput. Syst., vol. 16, no. 1, p. 26, 2016.
M. Curtis-Maury et al., “Identifying energy- efficient concurrency levels using machine learning,” in Proc. IEEE Int. Conf. Cluster Comput., Sep. 2007, pp. 488–495.
M. Stephenson and S. Amarasinghe, “Predicting unroll factors using supervised classification,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2005, pp. 123–134.
J. Cavazos, G. Fursin, F. Agakov, E. Bonilla, M. F. P. O’Boyle, and O. Temam, “Rapidly selecting good compiler optimizations using performance counters,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2007, pp. 185–197.
J. Cavazos and M. F. P. O’Boyle, “Method- specific dynamic compilation using logistic regression,” in Proc. 21st Annu. ACM SIGPLAN Conf. Object-Oriented Program. Syst. Lang. Appl. (OOPSLA), 2006, pp. 229–240.
C. Dubach, J. Cavazos, B. Franke, G. Fursin, M. F. O’Boyle, and O. Temam, “Fast compiler optimization evaluation using code-feature based performance prediction,” in Proc. 4th Int. Conf. Comput. Frontiers (CF), 2007, pp. 131–142.
T. Yuki, L. Renganarayanan, S. Rajopadhye, C. Anderson, A. E. Eichenberger, and K. O’Brien, “Automatic creation of tile size selection models,” in Proc. 8th Annu. IEEE/ ACM Int. Symp. Code Generat. Optim. (CGO), 2010, pp. 190–199.
A. M. Malik, “Optimal tile size selection problem using machine learning,” in Proc. Optim. Tile Size Selection Problem Using Mach. Learn., vol. 2. Dec. 2012, pp. 275–280.
R. W. Moore and B. R. Childers, “Building and using application utility models to dynamically choose thread counts,” J. Supercomput., vol. 68, no. 3, pp. 1184–1213, 2014.
Y. Liu, E. Z. Zhang, and X. Shen, “A cross- input adaptive framework for GPU program optimizations,” in Proc. IEEE Int. Symp. Parallel Distrib. Process., May 2009, pp. 1–10.
E. Perelman, G. Hamerly, M. Van Biesbrouck, T. Sherwood, and B. Calder, “Using simpoint for accurate and efficient simulation,” in Proc. ACM SIGMETRICS Int. Conf. Meas. Modeling Comput. Syst., 2003, pp. 318–319.
Y. Zhang, D. Meisner, J. Mars, and L. Tang, “Treadmill: Attributing the source of tail latency through precise load testing and statistical inference,” in Proc. 43rd Int. Symp. Comput. Archit. (ISCA), 2016, pp. 456–468.
B. C. Lee, D. M. Brooks, B. R. de Supinski, M. Schulz, K. Singh, and S. A. McKee, “Methods of inference and learning for performance modeling of parallel applications,” in Proc. 12th ACM SIGPLAN Symp. Principles Pract. Parallel Program. (PPoPP), 2007, pp. 249–258.
M. Curtis-Maury, J. Dzierwa, C. D. Antonopoulos, and D. S. Nikolopoulos, “Online power-performance adaptation of multithreaded programs using hardware event-based prediction,” in Proc. 20th Annu. Int. Conf. Supercomput. (ICS), 2006, pp. 157–166.
P. E. Bailey, D. K. Lowenthal, V. Ravi, B. Rountree, M. Schulz, and B. R. de Supinski, “Adaptive configuration selection for power-constrained heterogeneous systems,” in Proc. 43rd Int. Conf. Parallel Process., 2014, pp. 371–380.
J. L. Berral et al., “Towards energy-aware scheduling in data centers using machine learning,” in Proc. 1st Int. Conf. Energy- Efficient Comput. Netw. (e-Energy), 2010, pp. 215–224.
D. D. Vento, “Performance optimization on a supercomputer with ctuning and the PGI compiler,” in Proc. 2nd Int. Workshop Adapt. Self-Tuning Comput. Syst. Exaflop Era (EXADAPT), 2012, pp. 12–20.
P.-J. Micolet, A. Smith, and C. Dubach, “A machine learning approach to mapping streaming workloads to dynamic multicore processors,” ACM SIGPLAN Notices, vol. 51, no. 5, pp. 113–122, 2016.
D. Grewe, Z. Wang, and M. F. P. O’Boyle, “Portable mapping of data parallel programs to OpenCL for heterogeneous systems,” in Proc. Proc. IEEE/ACM Int. Symp. Code Generation Optim. (CGO), Feb. 2013, pp. 1–10.
H. Yu and L. Rauchwerger, “Adaptive reduction parallelization techniques,” in Proc. 14th Int. Conf. Supercomput. (ICS), 2000, pp. 66–77.
H. Leather, E. Bonilla, and M. O’Boyle, “Automatic feature generation for machine learning based optimizing compilation,” in Proc. 7th Annu. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), Mar. 2009, pp. 81–91.
Z. Wang, D. Grewe, and M. F. P. O’Boyle, “Automatic and portable mapping of data parallel programs to opencl for GPU-based heterogeneous systems,” ACM Trans. Archit. Code Optim., vol. 11, no. 4, p. 42, 2014.
Y. Ding, J. Ansel, K. Veeramachaneni, X. Shen, U.-M. O’Reilly, and S. Amarasinghe, “Autotuning algorithmic choice for input sensitivity,” in Proc. 36th ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2015, pp. 379–390.
T. K. Ho, “Random decision forests,” in Proc. 3rd Int. Conf. Document Anal. Recognit. (ICDAR), vol. 1. 1995, pp. 278–282.
T. G. Dietterich, “Ensemble methods in machine learning,” in Proc. 1st Int. Workshop Multiple Classifier Syst. (MCS), 2000, pp. 1–15.
P. Lokuciejewski, F. Gedikli, P. Marwedel, and K. Morik, “Automatic WCET reduction by machine learning based heuristics for function inlining,” in Proc. 3rd Workshop Statistical Mach. Learn. Approaches Archit. Compilation (SMART), 2009, pp. 1–15.
S. Benedict, R. S. Rejitha, P. Gschwandtner, R. Prodan, and T. Fahringer, “Energy prediction of OpenMP applications using random forest modeling approach,” in Proc. IEEE Int. Parallel Distrib. Process. Symp. Workshop, May 2015, pp. 1251–1260.
R. S. Rejitha, S. Benedict, S. A. Alex, and S. Infanto, “Energy prediction of CUDA application instances using dynamic regression models,” Computing, vol. 99, no. 8, pp. 765–790, 2017.
C. Cummins, P. Petoumenos, Z. Wang, and H. Leather, “End-to-end deep learning of optimization heuristics,” in Proc. 26th Int. Conf. Parallel Archit. Compilation Techn. (PACT), 2017, pp. 219–232.
Z. Wang, G. Tournavitis, B. Franke, and M. F. P. O’Boyle, “Integrating profile-driven parallelism detection and machine-learning- based mapping,” ACM Trans. Archit. Code Optim., vol. 11, no. 1, p. 2, 2014.
B. Taylor, V. S. Marco, and Z. Wang, “Adaptive optimization for OpenCL programs on embedded heterogeneous systems,” in Proc. 18th Annu. ACM SIGPLAN/ SIGBED Conf. Lang. Compil. Tools Embedded Syst. (LCETS), 2017, pp. 11–20.
P. Zhang, J. Fang, T. Tang, C. Yang, and Z. Wang, “Auto-tuning streamed applications on Intel Xeon Phi,” in Proc. 32nd IEEE Int. Parallel Distrib. Process. Symp. (IPDPS), 2018.
P. J. Joseph, K. Vaswani, and M. J. Thazhuthaveetil, “A predictive performance model for superscalar processors,” in Proc. 39th Annu. IEEE/ACM Int. Symp. Microarchit. (MICRO), Dec. 2006, pp. 161–170.
A. Ganapathi, K. Datta, A. Fox, and D. Patterson, “A case for machine learning to optimize multicore performance,” in Proc. 1st USENIX Conf. Hot Topics Parallelism (HotPar), 2009, p. 1.
E. Deniz and A. Sen, “Using machine learning techniques to detect parallel patterns of multi-threaded applications,” Int. J. Parallel Program., vol. 44, no. 4, pp. 867–900, 2016.
[85] Y. LeCun, Y. Bengio, and G. Hinton, Deep Learning, 2015.
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2012, pp. 1097–1105.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778.
H. Lee, Y. Largman, P. Pham, and A. Y. Ng, “Unsupervised feature learning for audio classification using convolutional deep belief networks,” in Proc. 22nd Int. Conf. Neural Inf. Process. Syst. (NIPS), 2009, pp. 1096–1104.
M. Allamanis, E. T. Barr, P. Devanbu, and C. Sutton (2017). “A survey of machine learning for big code and naturalness.” [Online]. Available: https://arxiv.org/ abs/1709.06182
J. MacQueen, “Some methods for classification and analysis of multivariate observations,” in Proc. 5th Berkeley Symp. Math. Statist. Prob., 1967, pp. 281–297.
T. Sherwood, E. Perelman, G. Hamerly, and B. Calder, “Automatically characterizing large scale program behavior,” in Proc. 10th Int. Conf. Archit. Support Program. Lang. Operat. Syst. (ASPLOS), 2002, pp. 45–57.
Z. Wang and M. F. O’Boyle, “Partitioning streaming parallelism for multi-cores: A machine learning based approach,” in Proc. 19th Int. Conf. Parallel Archit. Compilation Techn. (PACT), 2010, pp. 307–318.
M. Newman, Networks: An Introduction. New York, NY, USA: Oxford Univ. Press, 2010.
L. G. Martins, R. Nobre, A. C. B. Delbem, E. Marques, and J. A. M. Cardoso, “Exploration of compiler optimization sequences using clustering-based selection,” in Proc. SIGPLAN/SIGBED Conf. Lang. Compil. Tools Embedded Syst. (LCTES), 2014, pp. 63–72.
L. Eeckhout, H. Vandierendonck, and K. D. Bosschere, “Workload design: Selecting representative program-input pairs,” in Proc. Int. Conf. Parallel Archit. Compilation Techn., 2002, pp. 83–94.
Y. Chen et al., “Evaluating iterative optimization across 1000 datasets,” in Proc. 31st ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2010, pp. 448–459.
A. H. Ashouri, G. Mariani, G. Palermo, and C. Silvano, “A Bayesian network approach for compiler auto-tuning for embedded processors,” in Proc. IEEE 12th Symp. Embedded Syst. Real-time Multimedia (ESTIMedia), Oct. 2014, pp. 90–97.
A. Phansalkar, A. Joshi, and L. K. John, “Analysis of redundancy and application balance in the spec cpu2006 benchmark suite,” in Proc. 34th Annu. Int. Symp. Comput. Archit. (ISCA), 2007, pp. 412–423.
P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Proc. 25th Int. Conf. Mach. Learn. (ICML), 2008, pp. 1096–1103.
[100] X. Gu, H. Zhang, D. Zhang, and S. Kim (2016). Deep API learning. [Online]. Available: https://arxiv.org/abs/1605.08535
B. Singer and M. Veloso, “Learning to construct fast signal processing implementations,” J. Mach. Learn. Res., vol. 3, pp. 887–919, Dec. 2002.
X. Li, M. J. Garzaran, and D. Padua, “Optimizing sorting with genetic algorithms,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2005, pp. 99–110.
J. Ansel et al., “Petabricks: A language and compiler for algorithmic choice,” in Proc. ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2009, pp. 38–49.
M. Harman, W. B. Langdon, Y. Jia, D. R. White, A. Arcuri, and J. A. Clark, “The GISMOE challenge: Constructing the Pareto program surface using genetic programming to find better programs (keynote paper),” in Proc. 27th IEEE/ACM Int. Conf. Autom. Softw. Eng. (ASE), Sep. 2012, pp. 1–14.
U. Garciarena and R. Santana, “Evolutionary optimization of compiler flag selection by learning and exploiting flags interactions,” in Proc. Genetic Evol. Comput. Conf. Companion (GECCO), 2016, pp. 1159–1166.
M. Zuluaga, E. Bonilla, and N. Topham, “Predicting best design trade-offs: A case study in processor customization,” in Proc. Design Autom. Test Eur. Conf. Exhibit. (DATE), 2012, pp. 1030–1035.
M. R. Jantz and P. A. Kulkarni, “Exploiting phase inter-dependencies for faster iterative compiler optimization phase order searches,” in Proc. Int. Conf. Compil. Archit. Synthesis Embedded Syst. (CASES), Oct. 2013, pp. 1–10.
E. Ipek, O. Mutlu, J. F. Martínez, and R. Caruana, “Self-optimizing memory controllers: A reinforcement learning approach,” in Proc. IEEE 35th Int. Symp. Comput. Archit. (ISCA), Jun. 2008, pp. 39–50.
B. Porter, M. Grieves, R. R. Filho, and D. Leslie, “Rex: A development platform and online learning approach for runtime emergent software systems,” in Proc. Usenix Conf. Symp. Oper. Syst. Design Implement., Nov. 2016, pp. 333–348.
J. Rao, X. Bu, C.-Z. Xu, L. Wang, and G. Yin, “Vconf: A reinforcement learning approach to virtual machines auto-configuration,” in Proc. 6th Int. Conf. Autonom. Comput. (ICAC), 2009, pp. 137–146.
M. G. Lagoudakis and M. L. Littman, “Algorithm selection using reinforcement learning,” in Proc. 7th Int. Conf. Mach. Learn. (ICML), 2000, pp. 511–518.
N. Mishra, J. D. Lafferty, H. Hoffmann, and C. Imes, “CALOREE: Learning control for predictable latency and low energy,” in Proc. 23rd Int. Conf. Archit. Support Program. Lang. Oper. Syst. (ASPLOS), 2018, pp. 184–198.
M. K. Emani and M. O’Boyle, “Change detection based parallelism mapping: Exploiting offline models and Online adaptation,” in Proc. 27th Int. Workshop Lang. Compil. Parallel Comput. (LCPC), 2014, pp. 208–223.
[114] Y. Li, “Deep reinforcement learning: An overview,” CoRR, 2017.
J. Ansel et al., “Opentuner: An extensible framework for program autotuning,” in Proc. PACT, 2014, pp. 303–316.
C. K. Williams and C. E. Rasmussen, “Gaussian processes for regression,” in Proc. Adv. Neural Inf. Process. Syst., 1996, pp. 514–520.
C. E. Rasmussen and C. K. Williams, Gaussian Processes for Machine Learning, vol. 1. Cambridge, MA, USA: MIT Press, 2006.
M. K. Emani and M. O’Boyle, “Celebrating diversity: A mixture of experts approach for runtime mapping in dynamic environments,” in Proc. 36th ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2015, pp. 499–508.
H. D. Nguyen and F. Chamroukhi (2017). “An introduction to the practical and theoretical aspects of mixture-of-experts modeling.” [Online]. Available: https:// arxiv.org/abs/1707.03538
R. Polikar, “Ensemble based systems in decision making,” IEEE Circuits Syst. Mag., vol. 6, no. 3, pp. 21–45, Sep. 2006.
L. Rokach, “Ensemble-based classifiers,” Artif. Intell. Rev., vol. 33, nos. 1–2, pp. 1–39, 2010.
Y. Jiang et al., “Exploiting statistical correlations for proactive prediction of program behaviors,” in Proc. 8th Annu. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), Apr. 2010, pp. 248–256.
V. S. Marco, B. Taylor, B. Porter, and Z. Wang, “Improving spark application throughput via memory aware task co-location: A mixture of experts approach,” in Proc. ACM/IFIP/USENIX Middleware Conf., 2017, pp. 95–108.
B. Singer and M. M. Veloso, “Learning to predict performance from formula modeling and training data,” in Proc. 7th Int. Conf. Mach. Learn. (ICML), 2000, pp. 887–894.
E. Park, J. Cavazos, and M. A. Alvarez, “Using graph-based program characterization for predictive modeling,” in Proc. 10th Int. Symp. Code Generat. Optim. (CGO), 2012, pp. 196–206.
A. M. Malik, “Spatial based feature generation for machine learning based optimization compilation,” in Proc. 9th Int. Conf. Mach. Learn. Appl., 2010, pp. 925–930.
M. Burtscher, R. Nasre, and K. Pingali, “A quantitative study of irregular programs on GPUs,” in Proc. IEEE Int. Symp. Workload Characterization (IISWC), Nov. 2012, pp. 141–151.
Y. Luo, G. Tan, Z. Mo, and N. Sun, “Fast: A fast stencil autotuning framework based on an optimal-solution space model,” in Proc. 29th ACM Int. Conf. Supercomput., 2015, pp. 187–196.
S. Browne, J. Dongarra, N. Garner, G. Ho, and P. Mucci, “A portable programming interface for performance evaluation on modern processors,” Int. J. High Perform. Comput. Appl., vol. 14, no. 3, pp. 189–204, 2000.
T. Mytkowicz, A. Diwan, M. Hauswirth, and P. F. Sweeney, “Producing wrong data without doing anything obviously wrong!” in Proc. 14th Int. Conf. Archit. Support Program. Lang. Operat. Syst. (ASPLOS XIV), 2009, pp. 265–276.
J. Cavazos et al., “Automatic performance model construction for the fast software exploration of new hardware designs,” in Proc. Int. Conf. Compil. Archit. Synthesis Embedded Syst. (CASES), 2006, pp. 24–34.
S. Khan, P. Xekalakis, J. Cavazos, and M. Cintra, “Using predictivemodeling for cross-program design space exploration in multicore systems,” in Proc. IEEE 16th Int. Conf. Parallel Archit. Compilation Techn., Sep. 2007, pp. 327–338.
M. Namolaru, A. Cohen, G. Fursin, A. Zaks, and A. Freund, “Practical aggregation of semantical program properties for machine learning based optimization,” in Proc. Proc. Int. Conf. Compil. Archit. Synth. Embedded Syst. (CASES), 2010, pp. 197–206.
C. M. Bishop, Pattern Recognition and Machine Learning (Information Science and Statistics). Secaucus, NJ, USA: Springer- Verlag, 2006.
K. Hoste, A. Phansalkar, L. Eeckhout, A. Georges, L. K. John, and K. de Bosschere, “Performance prediction based on inherent program similarity,” in Proc. IEEE Int. Conf. Parallel Archit. Compilation Techn. (PACT), Swep. 2006, pp. 114–122.
N. E. Rosenblum, B. P. Miller, and X. Zhu, “Extracting compiler provenance from program binaries,” in Proc. 9th ACM SIGPLAN-SIGSOFT Workshop Program Anal. Softw. Tools Eng. (PASTE), 2010, pp. 21–28.
A. Bhattacharyya, G. Kwasniewski, and T. Hoefler, “Using compiler techniques to improve automatic performance modeling,” in Proc. Int. Conf. Parallel Archit. Compilation (PACT), 2015, pp. 468–479.
M. E. Taylor, K. E. Coons, B. Robatmili, B. A. Maher, D. Burger, and K. S. McKinley, “Evolving compiler heuristics to manage communication and contention,” in Proc. 24th Conf. Artif. Intell. (AAAI), 2010, pp. 1690–1693.
P.-S. Ting, C.-C. Tu, P.-Y. Chen, Y.-Y. Lo, and S.-M. Cheng (2016). “FEAST: An automated feature selection framework for compilation tasks.” [Online]. Available: https://arxiv.org/abs/1610.09543
E. Park, C. Kartsaklis, and J. Cavazos, “HERCULES: Strong patterns towards more intelligent predictive modeling,” in Proc. 43rd Int. Conf. Parallel Process., 2014, pp. 172–181.
K. Beyer, J. Goldstein, R. Ramakrishnan, and U. Shaft, “When is ‘nearest neighbor’ meaningful?” in Proc. Int. Conf. Database Theory, 1999, pp. 217–235.
I. Fodor, “A survey of dimension reduction techniques,” Lawrence Livermore Nat. Lab., Tech. Rep., 2002.
J. Thomson, M. F. O’Boyle, G. Fursin, and B. Franke, “Reducing training time in a one-shot machine learning-based compiler,” Lang. Compil. Parallel Comput., vol. 5898, pp. 399–407, 2009.
Y. Bengio, “Learning deep architectures for AI,” Found. Trends Mach. Learn., vol. 2, no. 1, pp. 1–127, 2009.
L. Deng, M. L. Seltzer, D. Yu, A. Acero, A.-R. Mohamed, and G. Hinton, “Binary coding of speech spectrograms using a deep auto-encoder,” in Proc. 11th Annu. Conf. Int. Speech Commun. Assoc., 2010.
L. Mou, G. Li, L. Zhang, T. Wang, and Z. Jin, “Convolutional neural networks over tree structures for programming language processing,” in Proc. AAAI, 2016, pp. 1287–1293.
M. White, M. Tufano, C. Vendome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection,” in Proc. ASE 31st IEEE/ACM Int. Conf. Autom. Softw. Eng., 2016, pp. 87–98.
C. Cummins, P. Petoumenos, Z. Wang, and H. Leather, “Synthesizing benchmarks for predictive modeling,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2017, pp. 86–99.
M. White, M. Tufano, and M. Martinez, M. Monperrus, and D. Poshyvanyk (2017). “Sorting and transforming program repair ingredients via deep learning code similarities.” [Online]. Available: https:// arxiv.org/abs/1707.04742
L. Almagor et al., “Finding effective compilation sequences,” in Proc. ACM SIGPLAN/SIGBED Conf. Lang. Compil. Tools Embedded Syst. (LCTES), 2004, pp. 231–239.
K. D. Cooper et al., “ACME: Adaptive compilation made efficient,” in Proc. ACM SIGPLAN/SIGBED Conf. Lang. Compil. Embedded Syst. (LCTES), 2005, pp. 69–77.
A. H. Ashouri, A. Bignoli, G. Palermo, C. Silvano, S. Kulkarni, and J. Cavazos, “MiCOMP: Mitigating the compiler phase- ordering problem using optimization sub- sequences and machine learning,” ACM Trans. Archit. Code Optim., vol. 14, no. 3, p. 29, 2017.
K. D. Cooper, D. Subramanian, and L. Torczon, “Adaptive optimizing compilers for the 21st century,” J. Supercomput., vol. 23, no. 1, pp. 7–22, 2002.
D. R. White, A. Arcuri, and J. A. Clark, “Evolutionary improvement of programs,” IEEE Trans. Evol. Comput., vol. 15, no. 4, pp. 515–538, Aug. 2011.
G. Fursin and O. Temam, “Collective optimization: A practical collaborative approach,” ACM Trans. Archit. Code Optim., vol. 7, no. 4, p. 20, Dec. 2010.
J. Kukunas, R. D. Cupper, and G. M. Kapfhammer, “A genetic algorithm to improve linux kernel performance on resource-constrained devices,” in Proc. 12th Annu. Conf. Companion Genetic Evol. Comput. (GECCO), 2010, pp. 2095–2096.
L.-N. Pouchet, C. Bastoul, A. Cohen, and J. Cavazos, “Iterative optimization in the polyhedral model: Part II, multidimensional time,” in Proc. 29th ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2008, pp. 90–100.
K. Asanovic et al., “The landscape of parallel computing research: A view from Berkeley,” Univ. California, Berkeley, CA, USA, Tech. Rep. UCB/EECS-2006-183, 2006.
Y. Zhang, M. Voss, and E. S. Rogers, “Runtime empirical selection of loop schedulers on hyperthreaded SMPs,” in Proc. 19th IEEE Int. Parallel Distrib. Process. Symp. (IPDPS), Apr. 2005, p. 44b.
D. Rughetti, P. D. Sanzo, B. Ciciani, and F. Quaglia, “Machine learning-based self- adjusting concurrency in software transactional memory systems,” in Proc. IEEE 20th Int. Symp. Modeling Anal. Simulation Comput. Telecommun. Syst., Aug. 2012, pp. 278–285.
C. Delimitrou and C. Kozyrakis, “Quasar: Resource-efficient and Qos-aware cluster management,” in Proc. 19th Int. Conf. Archit. Support Program. Lang. Operat. Syst. (ASPLOS), 2014, pp. 127–144.
X. Chen and S. Long, “Adaptive multi- versioning for openmp parallelization via machine learning,” in Proc. 15th Int. Conf. Parallel Distrib. Syst. (ICPADS), 2009, pp. 907–912.
M. Castro, L. F. W. Góes, C. P. Ribeiro, M. Cole, M. Cintra, and J. F. Méhaut, “A machine learning-based approach for thread mapping on transactional memory applications,” in Proc. 18th Int. Conf. High Perform. Comput., 2011, pp. 1–10.
C. Jung, S. Rus, B. P. Railing, N. Clark, and S. Pande, “Brainy: Effective selection of data structures,” in Proc. 32nd ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2011, pp. 86–97.
Z. Wang and M. F. P. O’Boyle, “Using machine learning to partition streaming programs,” ACM Trans. Archit. Code Optim., vol. 10, no. 3, p. 20, 2013.
C. Chan, J. Ansel, Y. L. Wong, S. Amarasinghe, and A. Edelman, “Autotuning multigrid with petabricks,” in Proc. ACM/IEEE Conf. Supercomput. (SC), 2009, Art. no. 5.
M. Pacula, J. Ansel, S. Amarasinghe, and U.-M. O’Reilly, “Hyperparameter tuning in bandit-based adaptive operator selection,” in Proc. Eur. Conf. Appl. Evol. Comput. (EuroSys), 2012, pp. 73–82.
J. Ansel, “Siblingrivalry: Online autotuning through local competitions,” in Proc. Int. Conf. Compil., Archit. Synth. Embedded Syst. (CASES), 2012, pp. 91–100.
M. J. Voss and R. Eigemann, “High-level adaptive program optimization with adapt,” in Proc. 8th ACM SIGPLAN Symp. Principles Pract. Parallel Program. (PPoPP), 2001, pp. 93–102.
A. Tiwari and J. K. Hollingsworth, “Online adaptive code generation and tuning,” in Proc. IEEE Int. Parallel Distrib. Process. Symp. (IPDPS), May 2011, pp. 879–892.
J. Ren, L. Gao, H. Wang, and Z. Wang, “Optimise Web browsing on heterogeneous mobile platforms: A machine learning based approach,” in Proc. IEEE Int. Conf. Comput. Commun. (INFOCOM), May 2017, pp. 1–9.
Y. Zhu and V. J. Reddi, “High-performance and energy-efficient mobile Web browsing on big/little systems,” in Proc. HPCA, Feb. 2013, pp. 13–24.
Z. Wang, M. F. P. O’Boyle, and M. K. Emani, “Smart, adaptive mapping of parallelism in the presence of external workload,” in Proc. IEEE/ACM Int. Symp. Code Generat. Optim. (CGO), Feb. 2013, pp. 1–10.
D. Grewe, Z. Wang, and M. F. P. O’Boyle, “A workload-aware mapping approach for data-parallel programs,” in Proc. 6th Int. Conf. High Perform. Embedded Archit. Compil. (HiPEAC), 2011, pp. 117–126.
D. Grewe, Z. Wang, and M. F. O’Boyle, “OpenCL task partitioning in the presence of GPU contention,” in Proc. Int. Workshop Lang. Compil. Parallel Comput., 2013, pp. 87–101.
L. Tang, J. Mars, and M. L. Soffa, “Compiling for niceness: Mitigating contention for Qos in warehouse scale computers,” in Proc. 10th Int. Symp. Code Generat. Optim. (CGO), 2012, pp. 1–12.
L. Tang, J. Mars, W. Wang, T. Dey, and M. L. Soffa, “Reqos: Reactive static/ dynamic compilation for Qos in warehouse scale computers,” in Proc. 18th Int. Conf. Archit. Support Program. Lang. Oper. Syst. (ASPLOS), 2013, pp. 89–100.
A. Matsunaga and J. A. B. Fortes, “On the use of machine learning to predict the time and resources consumed by applications,” in Proc. 10th IEEE/ACM Int. Conf. Cluster Cloud Grid Comput. (CCGRID), 2010, pp. 495–504.
S. Venkataraman, Z. Yang, M. J. Franklin, B. Recht, and I. Stoica, “Ernest: Efficient performance prediction for large-scale advanced analytics,” in Proc. NSDI, 2016, pp. 363–378.
S. Sankaran, “Predictive modeling based power estimation for embedded multicore systems,” in Proc. ACM Int. Conf. Comput. Frontiers (CF), 2016, pp. 370–375.
Y. Zhang, M. A. Laurenzano, J. Mars, and L. Tang, “Smite: Precise QoS prediction on real-system smt processors to improve utilization in warehouse scale computers,” in Proc. 47th Annu. IEEE/ACM Int. Symp. Microarchit. (MICRO-47), Dec. 2014, pp. 406–418.
V. Petrucci, “Octopus-man: QoS-driven task management for heterogeneous multicores in warehouse-scale computers,” in Proc. IEEE 21st Int. Symp. High Perform. Comput. Archit. (HPCA), Feb. 2015, pp. 246–258.
N. J. Yadwadkar, B. Hariharan, J. E. Gonzalez, and R. Katz, “Multi-task learning for straggler avoiding predictive job scheduling,” J. Mach. Learn. Res., vol. 17, no. 1, pp. 3692–3728, 2016.
Y. David and E. Yahav, “Tracelet-based code search in executables,” in Proc. 35th ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2014, pp. 349–360.
Y. David, N. Partush, and E. Yahav, “Statistical similarity of binaries,” in Proc. 37th ACM SIGPLAN Conf. Program. Lang. Design Implement. (PLDI), 2016, pp. 266–280.
E. Wong, T. Liu, and L. Tan, “Clocom: Mining existing source code for automatic comment generation,” in Proc. IEEE 22nd Int. Conf. Softw. Anal. Evol. Reeng. (SANER), Mar. 2015, pp. 380–389.
J. Fowkes and C. Sutton, “Parameter-free probabilistic api mining across GitHub,” in Proc. 24th ACM SIGSOFT Int. Symp. Found. Softw. Eng. (FSE), 2016, pp. 254–265.
A. T. Nguyen et al., “API code recommendation using statistical learning from fine-grained changes,” in Proc. 24th ACM SIGSOFT Int. Symp. Found. Softw. Eng. (FSE), 2016, pp. 511–522.
V. Raychev, P. Bielik, and M. Vechev, “Probabilistic model for code with decision trees,” in Proc. ACM SIGPLAN Int. Conf. Object-Oriented Program. Syst. Lang. Appl. (OOPSLA), 2016, pp. 731–747.
B. Bichsel, V. Raychev, P. Tsankov, and M. Vechev, “Statistical deobfuscation of Android applications,” in Proc. ACM SIGSAC Conf. Comput. Commun. Secur. (CCS), 2016, pp. 343–355.
P. Balaprakash, R. B. Gramacy, and S. M. Wild, “Active-learning-based surrogate models for empirical performance tuning,” in Proc. IEEE Int. Conf. Cluster Comput. (CLUSTER), Sep. 2013, pp. 1–8.
W. F. Ogilvie, P. Petoumenos, Z. Wang, and H. Leather, “Fast automatic heuristic construction using active learning,” in Proc. Int. Workshop Lang. Compil. Parallel Comput., 2014, pp. 146–160.
M. Zuluaga, G. Sergent, A. Krause, and M. Püschel, “Active learning for multi- objective optimization,” in Proc. Int. Conf. Mach. Learn., 2013, pp. 462–470.
W. F. Ogilvie, P. Petoumenos, Z. Wang, and H. Leather, “Minimizing the cost of iterative compilation with active learning,” in Proc. Int. Symp. Code Generat. Optim. (CGO), 2017, pp. 245–256.
[195] A. Evaluation. About Artifact Evaluation. [Online]. Available: http://www.artifact- eval.org/about.html
cTuning Foundation. Artifact Evaluation for Computer Systems Research. [Online]. Available: http://ctuning.org/ae/
About the Authors
郑望于2011年获得英国爱丁堡大学计算机科学博士学位。目前,他是英国兰卡斯特大学的助理教授,并领导分布式系统研究小组。2005年至2007年期间,他曾在IBM中国担任研发工程师。他的研究方向包括并行编译器、运行时系统、代码安全以及机器学习在这些领域优化问题中的应用。郑教授因其在基于机器学习的编译器优化方面的研究成果,曾获得三次最佳论文奖(分别为PACT’10、CGO’17和PACT’17)。
迈克尔·奥博伊尔(Michael O’Boyle)是英国爱丁堡大学计算机科学教授,HiPEAC的创始成员,爱丁堡大学ARM研究卓越中心主任,以及英国工程与物理科学研究委员会(EPSRC)普适并行性博士培训中心主任。他以将机器学习融入编译与并行化领域而闻名,致力于自动化优化技术的设计与构建。他已发表超过100篇学术论文,并获得三次最佳论文奖。奥博伊尔教授是EPSRC高级研究员和英国计算机学会(BCS)会士,并于2017年获得了ACM国际代码生成与优化研讨会(ACM CGO)“时代测试奖”。 )
)




