
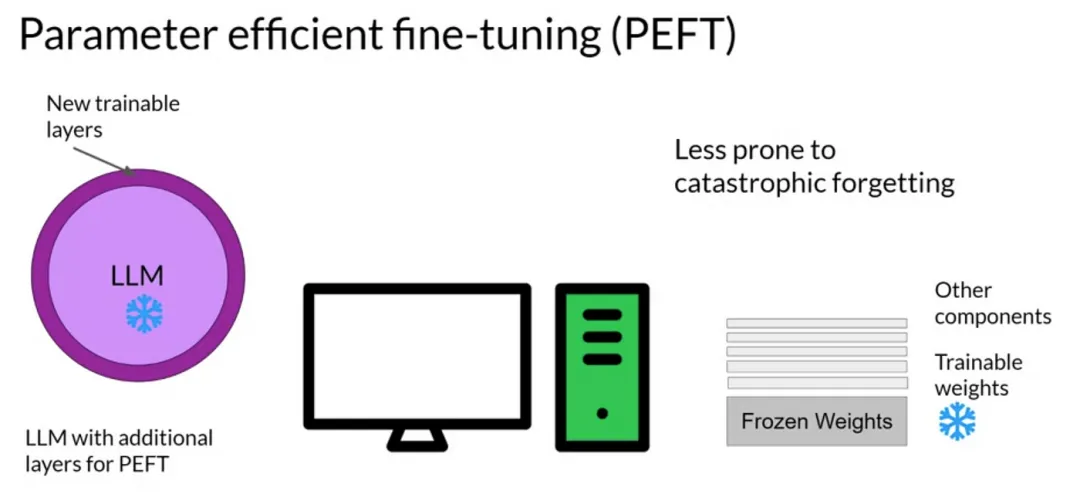
PEFT
Parameter efficient fine-tuning
PEFT(Parameter-Efficient Fine-Tuning)是一种在保持预训练模型大部分参数不变的情况下,通过仅调整少量额外参数来适应新任务的技术。这些额外参数可以是新添加的嵌入层、低秩矩阵或其他类型的参数,它们被用来“引导”或“调整”预训练模型的输出,以使其更适合新任务。
PEFT的主要方法包括:
- Prefix Tuning
- Prefix Tuning通过在模型输入层之前添加可训练的前缀嵌入(prefix embeddings)来影响模型的输出。这些前缀嵌入与原始输入拼接后一起输入到模型中,而模型的其他部分保持不变。
- LoRA
- LoRA通过在原始模型权重矩阵附近添加一个低秩矩阵来近似模型参数的更新。这种方法通过优化这个低秩矩阵来实现微调,而不需要修改原始模型参数。
- Adapter Tuning
- Adapter Tuning通过在模型的每个层之间插入小型神经网络(称为adapters)来实现微调。这些adapters包含可训练的权重,而模型的原始参数保持不变。
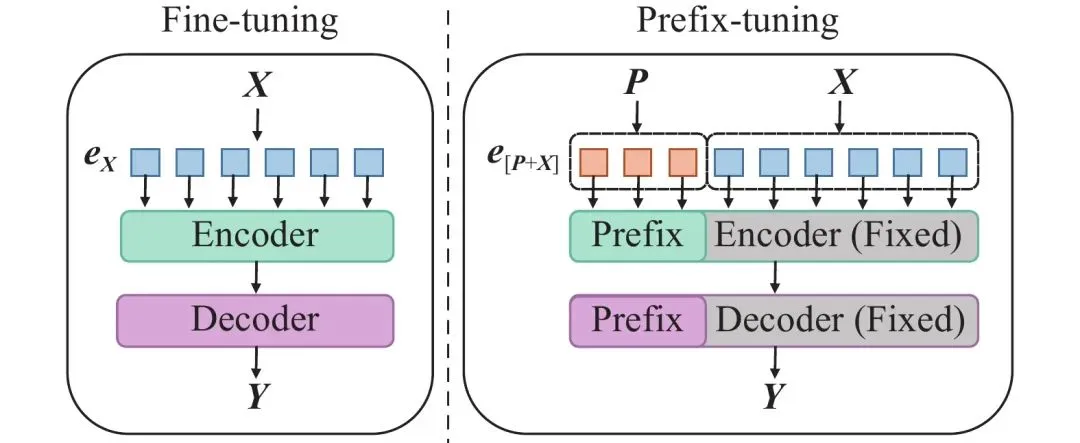
Prefix Tuning
Prefix Tuning 在原始文本进行词嵌入之后,在前面拼接上一个前缀矩阵,或者将前缀矩阵拼在模型每一层的输入前。
这个前缀与输入序列一起作为注意力机制的输入,从而影响模型对输入序列的理解和表示。由于前缀是可学习的,它可以在微调过程中根据特定任务进行调整,使得模型能够更好地适应新的领域或任务。
[!d]
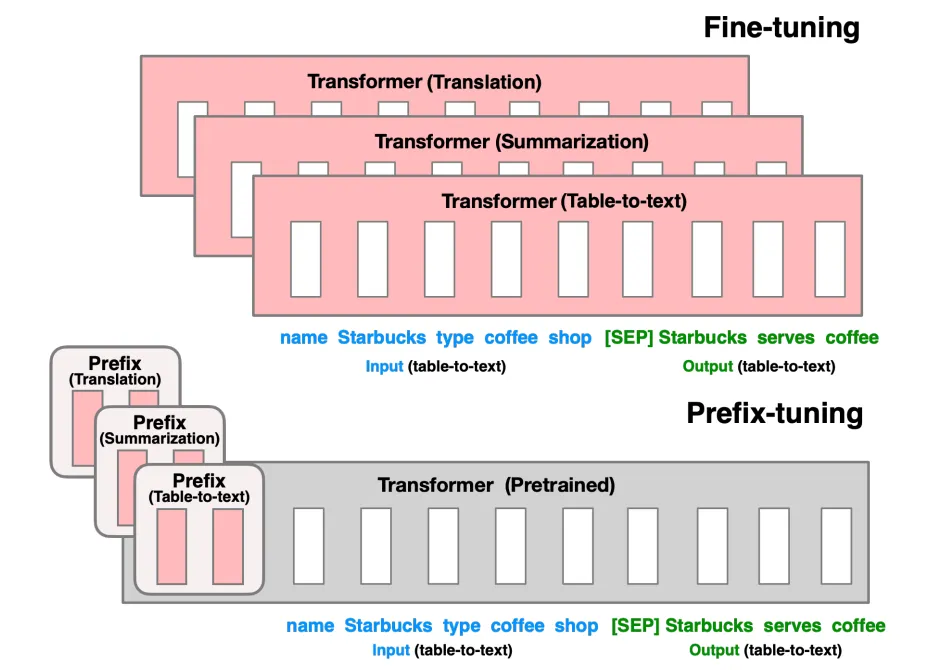
假设我们有一个大规模的预训练语言模型,比如 GPT。通常情况下,微调会调整整个模型的参数。但在 Prefix-tuning 中,我们为模型输入添加一个特定的前缀,这个前缀是一个小的、可训练的向量序列,它在训练过程中学习如何引导模型生成期望的输出。例如,假设我们希望模型生成关于“气候变化”的文本,而不改变模型的其他部分。我们可以为模型添加一个“气候变化相关”的前缀,比如:
"气候变化的影响: "在训练过程中,这个前缀的向量会被学习并优化,指导模型生成与气候变化相关的内容。模型的其他参数保持不变,训练的开销较小,且能更好地利用预训练模型的知识。
LoRA
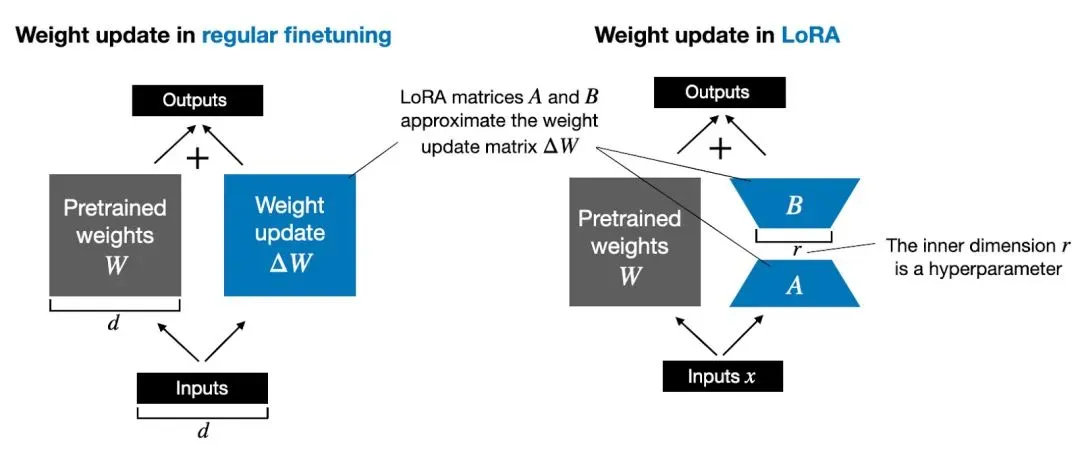
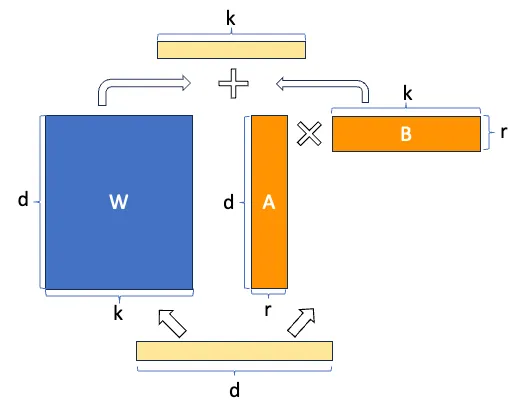
在传统的微调过程中,我们直接调整预训练模型的所有参数,这往往需要大量的计算资源。而 LoRA 采用了 低秩矩阵 的思想,将微调任务转化为仅优化少量新增的参数。
具体来说,LoRA 在模型的权重矩阵中引入了两个低秩矩阵 A 和 B ,用来近似原始矩阵的变化。这样,模型的主要参数(如大规模的权重矩阵)保持不变,而 LoRA 只对新增的小矩阵进行训练。其基本的数学公式如下:
其中, W 是原始的权重矩阵, A 和 B 是低秩矩阵,且这两个矩阵的秩通常远小于原始矩阵的秩。训练过程中,只需要调整 A 和 B ,而原始模型的权重 W 则不变。
[!d]
假设我们有一个大型的语言模型,原本这个模型有数亿甚至数十亿个参数。在传统微调中,我们会直接优化所有这些参数。而在 LoRA 中,我们为每个层的权重矩阵 W 添加两个低秩矩阵 A 和 B ,仅对这些新增的矩阵进行训练。这样,模型的主体部分不发生变化,只有少量额外的参数被调整。
[!c]
什么是低秩矩阵:低秩矩阵的秩(即矩阵中最大的线性无关行或列向量的个数)远小于矩阵的行数或列数。(低秩矩阵 强调的是矩阵的秩较小,表示矩阵的列或行可以由少数几个向量表示,而矩阵的元素分布不一定是零。)
LoRA将预训练模型的权重矩阵的增量(即微调前后的权重差异)分解为一个低秩矩阵A和一个原始矩阵B的乘积,即ΔW = AB。在微调过程中,仅训练低秩矩阵A的参数,而保持原始矩阵B和预训练模型的其他部分不变。
LoRA参数主要包括秩(lora_rank,影响性能和训练时间)、缩放系数(lora_alpha,确保训练稳定)、Dropout系数(lora_dropout,防止过拟合)和学习率(learning_rate,控制权重更新步长),它们共同影响模型微调的效果和效率。
参数
lora_rank:较小的秩(例如 1 或 2)意味着低秩矩阵更紧凑,所需的参数较少,但可能无法捕捉到模型所需的复杂性,从而影响模型的性能。较大的秩(例如 8 或 16)可以更好地表示复杂的任务,但会增加训练参数量,可能导致过拟合。lora_alpha:lora_alpha 是一个缩放系数,用于调整低秩矩阵 A 和 B 乘积的贡献大小。如果 lora_alpha 值太大,可能会导致 LoRA 的更新在训练中占据主导地位,从而破坏原始模型的学习能力。反之,如果值太小,LoRA 的贡献可能不足,导致微调效果不明显。lora_dropout:dropout 是一种正则化技术,它在训练过程中随机地忽略神经网络中的某些连接(即将其设置为零)。较高的 dropout 概率可以有效防止过拟合,特别是在训练数据量较小或模型复杂度较高时。
Adapter Tuning
Adapter Tuning的核心思想是在预训练模型的中间层中插入小的可训练层或“适配器”。这些适配器通常包括一些全连接层、非线性激活函数等,它们被设计用来捕获特定任务的知识,而不需要对整个预训练模型进行大规模的微调。
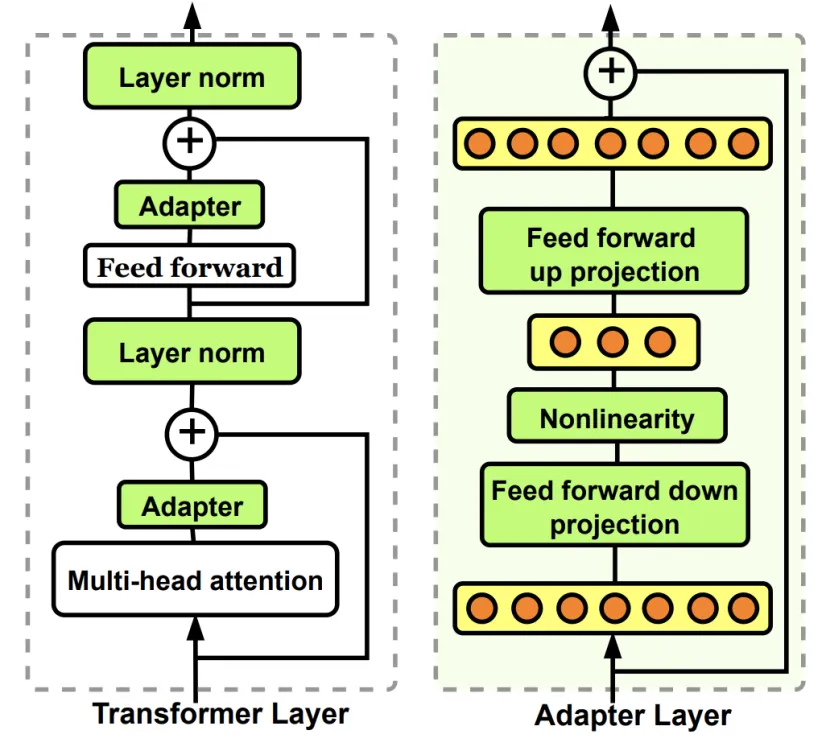
�练模型进行大规模的微调。




